AWS Deep Dives
Brief explanations of AWS services, organized by category for comprehensive understanding.
Security Services
Tools for identity and access management in AWS.
What is IAM?
AWS Identity and Access Management (IAM) is the global service that controls who (users, roles, applications) can perform what actions (e.g., read, write) on which AWS resources (e.g., S3 buckets, EC2 instances). Launched in 2011, it’s free, scalable, and integrates with all AWS services. IAM is the foundation of AWS security—enforcing permissions through policies to protect your account and enabling simple users/groups or complex enterprise federation.
How IAM Works
IAM operates as a centralized control plane—no regions, no VPCs. Every API request (e.g., s3:GetObject) is evaluated in real time:
- Identities: Users (e.g.,
alice), roles (e.g.,ec2-role), or federated identities make requests. - Policies: JSON documents define permissions—attached to identities or resources.
- Evaluation: IAM checks all policies, returning
AlloworDeny.- Default is implicit deny—nothing is allowed unless explicitly permitted.
- Explicit
Denyoverrides anyAllow.
Example: User bob tries s3:GetObject on my-bucket. IAM checks both his policy and the bucket’s policy—grants access only if both align.
Core Components
- Users: Permanent identities for humans or apps.
Credentials: console password, access keys (AKIA...), MFA. - Groups: Collections of users (e.g.,
developers) for shared policies. - Roles: Temporary identities for AWS services (e.g., EC2) or cross-account access. Assumed via STS with a trust policy:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": {"Service": "ec2.amazonaws.com"}, "Action": "sts:AssumeRole" } } - Policies: JSON permissions—e.g.:
Types: AWS Managed ({ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::my-bucket" } }AmazonS3ReadOnlyAccess), Customer Managed (custom), Inline (embedded).
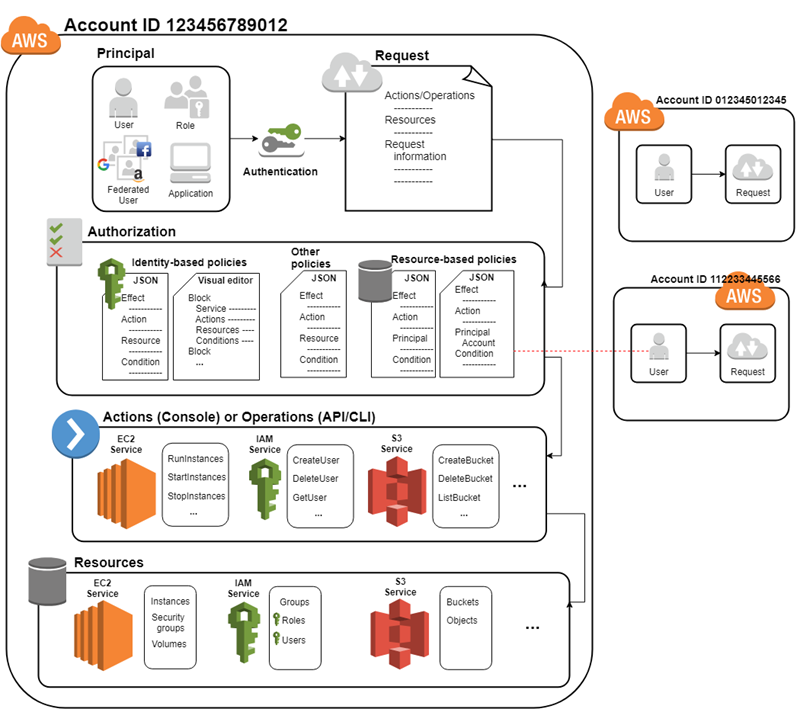
IAM Structure: Controls access—who, what, which AWS resource. Evaluates API requests in real-time against policies.
Key Features
- Multi-Factor Authentication (MFA): Enhances user/root account security by requiring a second factor (e.g., app code, YubiKey).
- Identity Federation: Connects external identities to IAM roles for SSO:
- SAML 2.0: Enterprise (e.g., Active Directory). Upload metadata:
Users sign in ataws iam create-saml-provider --saml-metadata-document file://adfs-metadata.xmlhttps://signin.aws.amazon.com/saml. - OIDC: Web apps (e.g., Google, GitHub). Configure:
aws iam create-open-id-connect-provider --url https://accounts.google.com --client-id-list "123.apps.googleusercontent.com" - Use Case: Developer logs into Google → assumes an IAM role → accesses AWS console without an IAM user.
- SAML 2.0: Enterprise (e.g., Active Directory). Upload metadata:
- Attribute-Based Access Control (ABAC): Tag-driven permissions. Example:
User{ "Effect": "Allow", "Action": "s3:*", "Resource": "*", "Condition": { "StringEquals": { "s3:ResourceTag/env": "dev", "aws:PrincipalTag/team": "devs" } } }alice(tagteam=devs) accesses S3 buckets taggedenv=dev. - Cross-Account Access: Role in Account A trusts Account B:
Bob assumes it:{ "Principal": {"AWS": "arn:aws:iam::987654321098:user/bob"} }aws sts assume-role --role-arn arn:aws:iam::123456789012:role/audit-role
Practical Examples
-
Secure an S3 Bucket: Create IAM user
alice:
Attach policy:aws iam create-user --user-name aliceaws iam attach-user-policy --user-name alice --policy-arn arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess -
EC2 Access to S3: Create role
ec2-s3:
Attachaws iam create-role --role-name ec2-s3 --assume-role-policy-document file://ec2-trust.jsonAmazonS3FullAccess, link to EC2 instance.
Additional Concepts & Best Practices
- Groups cannot contain other groups: IAM groups are collections of users only; you cannot nest groups within other groups.
- Policy Sid (Statement ID):
Sidis an optional field in policy statements for uniquely labeling each statement for easier management and auditing. - Principle of Least Privilege: Always grant only the minimum permissions required for users, groups, or roles to reduce security risk.
- Resource-Based Policies: Some AWS resources such as S3, SNS, and SQS support policies directly attached to the resource, controlling access separately from identity policies.
- IAM Permission Boundaries: Set boundaries at the user or role level to define the maximum permissions they can be granted, acting as a safeguard on top of regular policy attachments.
- Policy Evaluation Logic: IAM determines access by checking Explicit Deny, Organization Service Control Policies (SCPs, if AWS Organizations is used), Resource-based Policies, Permission Boundaries, and finally Identity-based Policies.
- Certificates with IAM: If you get SSL/TLS certificates from a third-party provider, you can import them into AWS Certificate Manager (ACM) or upload them to the IAM Certificate Store for use with specific AWS services.
Integration with AWS Identity Services
- AWS Cognito: Provides user directory (User Pools) for sign-up/sign-in and identity federation (Identity Pools) for temporary AWS credentials. Enables authentication for web, mobile, and federated users using social or enterprise IdPs. Recommended by AWS for managing application users.
- AWS Directory Service:
- Managed Microsoft AD: Fully managed Active Directory supporting integration with on-premises AD for enterprise-scale workloads and authentication.
- AD Connector: Proxy service to connect AWS resources to your on-premises Microsoft AD without storing data in the cloud.
- Simple AD: Basic standalone directory for simple use cases; not connectable to on-prem AD.
Limits and Pricing
Limits: Users: 5,000; Roles: 1,000; Groups: 300; Policies/user: 10; Policy size: 6,144 chars—soft limits, request increases.
Pricing: Core IAM: free. MFA: $12.99 (virtual), $20-$50 (hardware). Federation/STS: free (external IdP costs vary).
Compute Services
Scalable compute resources for running applications and workloads in AWS.
Overview
Amazon Elastic Compute Cloud (EC2) is AWS’s flagship compute service, offering resizable virtual servers in the cloud since 2006. It’s the backbone for running applications, hosting workloads, and scaling compute capacity without the overhead of physical hardware. EC2 provides granular control over CPU, memory, storage, and networking, making it a versatile choice for everything from web servers to machine learning clusters. Unlike serverless options like Lambda, EC2 requires you to manage the OS, patching, and scaling—think of it as renting a customizable computer in AWS’s data centers, billed by the second.
Architecture and Core Components
EC2 instances run on AWS’s global infrastructure, leveraging Xen or Nitro hypervisors (depending on instance type) across Availability Zones (AZs). Instances are launched from Amazon Machine Images (AMIs)—preconfigured templates with OS and software (e.g., Amazon Linux 2, Ubuntu 20.04). The Nitro System, introduced in 2017, offloads networking, storage, and security to dedicated hardware, boosting performance and isolation. Key components include:
- Instances: Virtual machines with defined resources (e.g., t3.micro: 2 vCPUs, 1 GB RAM). Launched in a VPC subnet with an Elastic Network Interface (ENI).
- AMIs: Stored in S3, AMIs are regional but shareable across accounts—create custom AMIs by snapshotting EBS volumes.
- Instance Metadata: Accessible at
http://169.254.169.254/latest/meta-data/—provides instance ID, IP, etc., for automation.
Instance Types and Families
EC2 offers a dizzying array of instance types, grouped into families optimized for specific workloads. Each type balances vCPU, memory, network, and storage:
- General Purpose (T, M): T3 (burstable, credits for CPU spikes, $0.0104/hr t3.micro), M5 (balanced, 25 Gbps networking)—e.g., web apps, small DBs.
- Compute Optimized (C): C5 (high CPU, 3.0 GHz Intel Xeon, up to 100 Gbps)—e.g., gaming servers, HPC.
- Memory Optimized (R, X): R5 (high RAM, 96 vCPUs, 768 GB)—e.g., in-memory DBs like Redis.
- Storage Optimized (I, D): I3 (NVMe SSDs, 15 TB local)—e.g., NoSQL DBs, data warehouses.
- GPU (G, P): G4 (NVIDIA T4, 16 GB GPU RAM)—e.g., ML training, video rendering.
Choosing the right type is an art—over-provisioning wastes money, under-provisioning kills performance. Use CloudWatch metrics (CPU, memory via agent) to right-size.
Storage Options
EC2 instances pair with storage for persistence and speed:
- EBS (Elastic Block Store): Network-attached SSD/HDD volumes (e.g., gp3: 3,000 IOPS base, $0.08/GB). Snapshots in S3 enable backups and AMI creation. Multi-Attach (io2) allows clustering.
- Instance Store: Ephemeral, local SSDs (e.g., 7.5 TB on i3.large)—high IOPS (up to 3.3M), lost on stop/termination. Use for temp data or caches.
- EFS/S3: Mountable file systems or object storage via ENI—EFS for shared files, S3 for off-instance data.
EBS is detachable—stop an instance, swap volumes, or resize (e.g., gp2 to gp3) without downtime.
Pricing and Purchase Options
EC2’s pricing is complex but flexible:
- On-Demand: Pay-per-second ($0.0104/hr t3.micro to $3+/hr GPU)—no commitment, ideal for testing.
- Reserved Instances (RI): 1-3 year contracts, ~40-70% off (e.g., t3.medium 3-yr All Upfront: ~$0.015/hr)—predictable workloads.
- Spot Instances: Bid on spare capacity, up to 90% off (e.g., c5.large ~$0.03/hr)—interruptible, use for batch jobs with Spot Fleets.
- Savings Plans: Commit to compute spend ($1/hr), applies across EC2/Lambda/Fargate—more flexible than RIs.
Free tier: 750 hrs/month of t2/t3.micro (1 yr)—great for learning. Data transfer out: $0.09/GB after 100 GB free.
Networking and Scaling
EC2 lives in a VPC—public/private subnets dictate access. ENIs provide IPs (private + optional Elastic IP); enhanced networking (ENA, up to 100 Gbps) boosts throughput. Scaling comes via:
- Auto Scaling Groups (ASG): Launch/terminate instances based on CloudWatch metrics (CPU > 70%)—spans AZs for HA.
- Elastic Load Balancer (ELB): ALB routes HTTP to EC2—e.g., path-based routing (
/apivs./web).
Example: A web app scales from 2 to 10 t3.medium instances across 2 AZs, balanced by ALB.
Use Cases and Scenarios
EC2’s versatility shines:
- Web Hosting: Nginx on t3.medium, EBS for persistence—scale with ASG.
- Batch Processing: Spot Instances crunch data (e.g., video encoding)—checkpoint to S3.
- ML Training: P3 instances with GPUs—EBS for datasets, S3 for outputs.
Edge Cases
Instance Limits: 20 On-Demand per region (soft)—request increases. Spot Interruptions: 2-minute warning—save state to EBS/S3. EBS Bottlenecks: High IOPS needs io2 (16,000 IOPS base)—costly.
Overview
AWS Lambda, introduced in 2014, is a serverless compute service that runs code in response to events without provisioning or managing servers. It’s a paradigm shift from EC2—AWS handles scaling, patching, and infrastructure, while you focus on code (functions). Lambda executes in ephemeral containers, billed by invocation and duration (ms), making it ideal for event-driven, short-lived tasks. From resizing S3 images to processing IoT streams, Lambda’s stateless nature and auto-scaling make it a cornerstone of modern architectures.
Architecture and Execution
Lambda’s backend is a black box—AWS spins up containers (Firecracker microVMs) on demand, running your code in isolated environments. Key elements:
- Functions: Code + config (e.g., Python 3.9, 512 MB RAM)—uploaded as ZIP or container images (up to 10 GB).
- Execution Environment: Includes runtime, libraries, and /tmp (512 MB)—stateless, but VPC adds ENIs.
- Triggers: S3, API Gateway, CloudWatch Events—events invoke functions asynchronously or synchronously.
Cold starts (initial container spin-up) add latency (ms to seconds)—minimized with Provisioned Concurrency or lightweight runtimes (e.g., Node.js vs. Java).
Limits and Configuration
Lambda has strict boundaries:
- Timeout: 15 minutes max—long tasks need EC2 or Step Functions.
- Memory: 128 MB to 10 GB—CPU scales proportionally (e.g., 1,769 vCPUs at 10 GB).
- Concurrency: 1,000 per region (soft)—bursts higher, throttles excess (use Reserved Concurrency).
Layers extend functions—e.g., share NumPy across functions. Environment variables configure dynamically (e.g., API keys).
Pricing
Pay-per-use: $0.20/1M requests, $0.0000167/GB-second. Free tier: 1M requests, 400,000 GB-seconds/month. Example: 1M 1-second runs at 1 GB = $16.67—cheaper than EC2 for sporadic tasks.
Use Cases
Event Processing: S3 upload triggers image resize. API Backends: API Gateway + Lambda for REST endpoints. Cron Jobs: CloudWatch schedules nightly tasks—e.g., DB cleanup.
Edge Cases
Cold Starts: Java + VPC = 10s delay—use Node.js or Provisioned Concurrency. Throttling: 1,000 limit blocks bursts—queue with SQS.
Overview
AWS Fargate, launched in 2017, is a serverless compute engine for containers, eliminating the need to manage EC2 instances while running Dockerized workloads. Built atop ECS (Elastic Container Service) and later extended to EKS (Elastic Kubernetes Service), Fargate abstracts the underlying infrastructure—define your container’s CPU and memory, and AWS handles provisioning, scaling, and patching. It’s a middle ground between EC2’s control and Lambda’s simplicity, ideal for microservices, batch jobs, or stateless apps needing more runtime flexibility than Lambda’s 15-minute limit.
Architecture and Core Components
Fargate runs containers in a managed cluster—AWS provisions virtualized compute resources behind the scenes, likely using Firecracker microVMs (similar to Lambda). Unlike EC2-based ECS, where you manage instances, Fargate tasks launch directly into a VPC with dedicated ENIs (Elastic Network Interfaces) for networking. Key components include:
- Tasks: The running container instance—defined by a Task Definition (JSON) specifying image (e.g.,
nginx:latest), CPU (256-16,384 units), memory (0.5-120 GB), and ports. - Services: Maintain a desired task count—e.g., 3 Nginx containers—with auto-scaling and load balancing via ALB.
- Cluster: A logical grouping of tasks—Fargate clusters don’t expose EC2, unlike ECS EC2 mode.
Tasks are isolated—each gets its own ENI in your VPC subnet, ensuring network security and private IPs. AWS handles OS updates, container orchestration, and resource allocation transparently.
Configuration and Limits
Fargate offers fine-grained resource allocation—CPU in 256-unit increments (1 vCPU = 1,024 units), memory in GB (e.g., 2 vCPUs + 4 GB). Limits include:
- Task Size: 256 CPU units (0.25 vCPU) to 16,384 (16 vCPUs), 512 MB to 120 GB RAM—combinable in specific ratios (e.g., 4 vCPUs needs 8-32 GB).
- Storage: 20-200 GB ephemeral per task (no EBS/Instance Store)—use EFS for persistence.
- Concurrency: 100 tasks per service default—scales with region limits (request increases).
Task Definitions support multiple containers (e.g., app + sidecar), logs route to CloudWatch, and IAM roles grant service access (e.g., S3).
Pricing
Fargate bills per-second for vCPU and GB-hour: $0.04048/vCPU-hour, $0.004445/GB-hour (us-east-1). Example: 1 vCPU + 2 GB for 1 hour = $0.04937—pricier than EC2 but no management overhead. Free tier: 400,000 GB-seconds/month shared with Lambda. Data transfer out: $0.09/GB after 100 GB free.
Networking and Scaling
Fargate integrates with VPC—tasks get private IPs (public via NAT/IGW). Use awsvpc mode—each task has an ENI, supporting Security Groups (e.g., port 80 inbound). Scaling happens via:
- ECS Services: Auto-scaling based on CloudWatch metrics (e.g., CPU > 70%)—adjusts task count.
- ALB/NLB: Load balances traffic—e.g., ALB routes
/apito Fargate tasks.
Example: Run 5 Node.js containers behind ALB, scaling to 10 on demand—zero server management.
Use Cases and Scenarios
Fargate shines where serverless meets containers:
- Microservices: Deploy 10 REST API containers—each 0.5 vCPU, 1 GB—scaled via ECS Service.
- Batch Jobs: Run data processing tasks—e.g., ETL pipeline with 4 vCPUs, EFS for input/output.
- CI/CD: Jenkins workers on Fargate—spin up on demand, shut down when idle.
Edge Cases and Gotchas
No Instance Access: Can’t SSH—debug via logs or exec (ECS). Ephemeral Storage: 200 GB max—EFS for more, but adds cost. Cold Starts: Slower than Lambda (seconds)—pre-warm with min task count. Pricing: Overkill for steady-state workloads—EC2 Spot cheaper.
Integration with Other Services
ECS/EKS: Fargate powers tasks—ECS for simplicity, EKS for Kubernetes. CloudWatch: Logs and metrics—e.g., CPU utilization. EFS: Persistent storage—e.g., shared configs. ALB: HTTP routing—e.g., path-based microservices.
Overview
Amazon Elastic Container Service (ECS), launched in 2014, is a fully managed container orchestration service that simplifies running Docker containers at scale. It’s AWS’s homegrown alternative to Kubernetes (EKS), offering tight integration with EC2 or Fargate for compute, and supporting microservices, batch jobs, and CI/CD pipelines. Unlike Lambda’s serverless simplicity or EC2’s raw control, ECS abstracts container management—define tasks, services, and clusters, and AWS handles scheduling, scaling, and health. It’s versatile, cost-effective, and a staple for containerized workloads.
Architecture and Core Components
ECS operates as a regional service, orchestrating containers across a cluster—either EC2 instances you manage or Fargate’s serverless compute. It uses a control plane (AWS-managed) and data plane (your compute). Key components:
- Clusters: Logical grouping of tasks/services—e.g.,
my-cluster—spans VPC subnets. - Task Definitions: JSON blueprints—e.g.,
nginx:latest, 0.5 vCPU, 1 GB RAM—define containers, ports, volumes. - Tasks: Running instances of Task Definitions—e.g., one-off job or long-running app.
- Services: Maintain task count—e.g., 3 Nginx tasks—with load balancing and auto-scaling.
- Container Agent: Runs on EC2—e.g.,
/ecs-agent—communicates with ECS control plane.
EC2 mode requires instance management (AMIs, patching); Fargate mode abstracts it—tasks get ENIs in your VPC. Scheduling uses capacity providers—e.g., Fargate vs. EC2 Spot.
Launch Types and Configuration
ECS supports two launch types:
- EC2: You manage instances—e.g., t3.medium cluster, 20 tasks max—full control, cheaper.
- Fargate: Serverless—e.g., 0.5 vCPU, 2 GB per task—256-16,384 CPU units, 0.5-120 GB RAM.
Config includes networking (awsvpc, bridge), IAM roles (task execution, task role), and logging (CloudWatch). Limits: 10,000 tasks/cluster, 120 tasks/service—soft limits, request increases.
Pricing
No direct ECS cost—pay for compute: EC2 (e.g., $0.0104/hr t3.micro), Fargate ($0.04048/vCPU-hr, $0.004445/GB-hr). Free tier: 400,000 GB-seconds/month (Fargate). Example: 3 tasks, 1 vCPU, 2 GB, 24 hrs = $3.55/day (Fargate)—EC2 cheaper with RIs.
Networking and Scaling
ECS integrates with VPC—awsvpc gives tasks ENIs (Security Groups, private IPs). Scaling via:
- Services: Desired count—e.g., 5 tasks—auto-scales with CloudWatch (CPU > 70%).
- ALB/NLB: Routes traffic—e.g., ALB path
/apito ECS service. - Capacity Providers: Mix EC2/Fargate—e.g., 80% Fargate, 20% Spot.
Example: 10-task service behind ALB scales to 20 on demand—Fargate handles provisioning.
Use Cases and Scenarios
Microservices: 5 APIs—e.g., user-service, 2 tasks each, ALB routing. Batch Jobs: ETL—e.g., 50 Fargate tasks process S3 data. CI/CD: Jenkins—e.g., EC2 cluster runs build containers.
Edge Cases and Gotchas
EC2 Overhead: Patching, scaling manual—use ASG. Fargate Cold Starts: Seconds—pre-warm with min tasks. Task Limits: 10,000/cluster—split large apps. Networking: awsvpc ENI limits—plan subnet IPs.
Integration with Other Services
Fargate: Serverless tasks—e.g., 1 vCPU jobs. ALB: HTTP routing—e.g., /users. CloudWatch: Logs/metrics—e.g., CPU alarms. EFS: Shared storage—e.g., /mnt/efs. IAM: Task roles—e.g., S3 access.
Overview
Elastic Load Balancer (ELB), introduced in 2009, is AWS’s managed load balancing service, distributing traffic across compute targets (EC2, Fargate, Lambda, etc.) to ensure availability, scalability, and fault tolerance. It offers four variants: Application Load Balancer (ALB) for Layer 7 (HTTP/HTTPS), Network Load Balancer (NLB) for Layer 4 (TCP/UDP), Gateway Load Balancer (GLB) for Layer 3 (IP routing), and Classic Load Balancer (CLB) for legacy apps. Fully managed and auto-scaling, ELB integrates with VPCs and spans AZs, offloading traffic management from your compute resources.
Architecture and Core Components
ELB runs in AWS’s edge and regional network, a distributed system (likely reverse proxies or routers) with no single point of failure. Common components across types:
- Load Balancer: Entry point—e.g.,
my-elb-123.us-east-1.elb.amazonaws.com—lives in a VPC. - Listeners: Protocols/ports—e.g., HTTP:80, TCP:443—route to targets.
- Target Groups: Compute endpoints—e.g., EC2, IPs—with health checks (except GLB).
Deployed in subnets—public (IGW) or private (NAT). Cross-zone balancing spreads traffic across AZs—optional for cost control.
ELB Variants
Each ELB type serves distinct needs:
- Application Load Balancer (ALB, 2016): Layer 7—HTTP/HTTPS routing via path (
/api), host (api.example.com), headers. Supports WebSockets, Lambda targets. Ideal for microservices, web apps. - Network Load Balancer (NLB, 2017): Layer 4—TCP/UDP, ultra-low latency (100s of microseconds), millions of requests/sec. Static IPs, preserves source IP. Suits high-throughput, real-time apps.
- Gateway Load Balancer (GLB, 2020): Layer 3—IP traffic routing to third-party appliances (e.g., firewalls, IDS). Transparent, uses GENEVE protocol. For network security/inspection.
- Classic Load Balancer (CLB, 2009): Legacy—Layer 4 (TCP) or 7 (HTTP). Basic balancing, no advanced routing. Deprecated—use ALB/NLB for new apps.
Features and Configuration
ALB: Rules (100/listener)—e.g., /users to ECS, sticky sessions (AWSALB cookie), SSL via ACM. NLB: Static IPs per AZ, TLS termination—e.g., TCP:443 to EC2. GLB: Appliance targets—e.g., Palo Alto VM, no health checks (endpoint-managed). CLB: Basic HTTP/TCP—e.g., port 80 to EC2. Limits: ALB 1,000 targets/group, NLB 200, CLB 100—soft limits.
Health Checks: ALB/CLB—HTTP 200 on /health; NLB—TCP ping; GLB—none. SSL: ALB/NLB/CLB—ACM or custom certs—e.g., TLS 1.3.
Pricing
Varies by type—pay-per-hour + capacity:
- ALB: $0.0225/hr + $0.008/LCU-hr (connections, bytes, rules)—e.g., 10 LCUs, 24 hrs = $0.78/day.
- NLB: $0.0225/hr + $0.006/NCU-hr (connections, bandwidth)—e.g., 5 NCUs = $0.54/day.
- GLB: $0.025/hr + $0.007/GCU-hr (traffic)—e.g., 5 GCUs = $0.58/day.
- CLB: $0.025/hr + $0.008/GB processed—e.g., 10 GB = $0.68/day.
Free tier: 750 hrs/month (shared). Data transfer: $0.09/GB out.
Networking and Scaling
VPC-integrated—public/private subnets. Scaling is automatic—e.g., ALB handles 10M requests/sec. Targets:
- ALB: Instance, IP, Lambda—e.g.,
i-12345678,/apito Fargate. - NLB: Instance, IP—e.g.,
10.0.1.5, TCP:3306 to RDS proxy. - GLB: IP—e.g.,
192.168.1.10to firewall appliance. - CLB: Instance only—e.g.,
i-12345678.
Example: ALB routes /web to 5 EC2, NLB sends TCP:443 to 10 Fargate—scales with load.
Use Cases and Scenarios
ALB: Microservices—e.g., /auth to ECS, HTTPS web apps. NLB: Real-time—e.g., gaming UDP to EC2, RDS proxy. GLB: Security—e.g., route VPC traffic via NGFW. CLB: Legacy—e.g., HTTP to old EC2 cluster.
Edge Cases and Gotchas
ALB: 100-rule limit—complex apps need multiple ALBs. NLB: Static IP cost—e.g., Elastic IP fees if detached. GLB: Appliance health—manual failover, no checks. CLB: Deprecated—lacks WebSockets, slow updates. Cross-Zone: Data cost—e.g., $0.01/GB AZ-to-AZ—disable if local. Drain: ALB/NLB—300s delay—tune for slow clients.
Integration with Other Services
EC2/ASG: ALB/NLB/CLB targets—e.g., scale 2-10 instances. ECS/Fargate: ALB/NLB—e.g., /api to service. Lambda: ALB—e.g., serverless proxy. CloudWatch: Metrics—e.g., ActiveConnectionCount, 5xx alarms. ACM: SSL—e.g., *.example.com. WAF: ALB—e.g., block XSS. VPC: GLB—e.g., route via appliances.
Overview
Auto Scaling Groups (ASG), part of AWS Auto Scaling since 2009, dynamically adjust the number of EC2 instances in a group based on demand, ensuring availability and cost efficiency. Unlike ECS services or Lambda’s auto-scaling, ASG gives you fine-grained control over instance provisioning—ideal for stateful apps, web servers, or batch processing. It pairs with ELB for load distribution and CloudWatch for triggers, making it a compute workhorse for elastic workloads.
Architecture and Core Components
ASG operates regionally, managing EC2 instances across AZs in a VPC. It’s a control layer atop EC2—no standalone compute. Key components:
- Launch Template/Configuration: Defines instance—e.g., t3.medium, AMI, EBS—replaces older Launch Configs.
- Group: Set of instances—e.g., 2-10 t3.micro—min, max, desired capacity.
- Scaling Policies: Rules—e.g., CPU > 70% adds 2 instances—simple, step, or target tracking.
Instances launch in subnets—e.g., 1 per AZ—health monitored via ELB or EC2 status. Termination respects oldest/newest or custom logic.
Features and Configuration
Policies: Target tracking (e.g., 50% CPU), step scaling (e.g., +2 at 80%), scheduled (e.g., 10 instances at 9 AM). Cooldown: Delay—e.g., 300s—prevents thrashing. Mixed Instances: Multiple types—e.g., t3 + c5, Spot + On-Demand. Limits: 20 instances default—soft limit.
Pricing
Free—pay for EC2: $0.0104/hr t3.micro (On-Demand), Spot ~$0.003/hr. Example: 5 t3.micro, 24 hrs = $1.25/day (On-Demand)—Spot slashes costs.
Networking and Scaling
ASG ties to VPC—subnets define AZ spread. Scaling triggers via:
- CloudWatch: Metrics—e.g.,
CPUUtilization,RequestCountPerTarget. - ELB: Health-based—e.g., replace unhealthy instances.
- Manual: Set desired—e.g., 8 instances now.
Example: Web app scales 2-10 instances across 2 AZs, ALB balances—CPU > 70% adds 2.
Use Cases and Scenarios
Web Hosting: Nginx cluster—e.g., 3-15 instances, ALB front. Batch Processing: Spot instances—e.g., 50 crunch data overnight. HA: Multi-AZ—e.g., min 2 per AZ.
Edge Cases and Gotchas
Cooldown: Slow response—e.g., 300s delays scaling. Spot Termination: 2-min warning—checkpoint often. AZ Imbalance: Subnet size limits—e.g., /28 caps at 14 IPs. Health Checks: ELB lag—use EC2 status for speed.
Integration with Other Services
EC2: Instance pool—e.g., t3.micro. ALB/NLB: Traffic spread—e.g., /web. CloudWatch: Triggers—e.g., CPU alarms. EBS: Persistent volumes—e.g., attach on launch. IAM: Instance roles—e.g., S3 access.
Overview
AWS Batch, launched in 2016, is a managed service for running batch computing workloads at scale, automating job scheduling and resource provisioning. Built on ECS, it’s tailored for data processing, simulations, or ETL—think “HPC lite” without cluster management. Unlike ECS’s general-purpose orchestration, Batch focuses on queue-based, finite jobs, using EC2 or Fargate under the hood, and optimizing cost with Spot Instances.
Architecture and Core Components
Batch is a regional service, orchestrating jobs via ECS clusters (EC2 or Fargate). It’s a scheduler atop compute resources. Key components:
- Jobs: Units of work—e.g., Python script in Docker—defined by Job Definitions.
- Job Definitions: Templates—e.g.,
my-job-def, 2 vCPUs, 4 GB,my-image:1.0. - Job Queues: Prioritized queues—e.g.,
high-priority—map to compute environments. - Compute Environments: Resource pools—e.g., EC2 Spot, Fargate—managed or unmanaged.
Jobs submit to queues, Batch schedules to environments—e.g., 100 jobs on 10 EC2 instances—retries failed tasks.
Features and Configuration
Priority: Queues ranked—e.g., 1 (high) vs. 10 (low). Retry: Configurable—e.g., 3 attempts on failure. Dependencies: Job B after A—e.g., ETL pipeline. Limits: 10,000 jobs/queue, 50 queues—soft limits.
Pricing
Free—pay for compute: EC2 ($0.0104/hr t3.micro), Fargate ($0.04048/vCPU-hr). Example: 10 jobs, 1 vCPU, 2 GB, 1 hr = $0.49 (Fargate)—Spot cuts to ~$0.15.
Networking and Scaling
VPC-based—jobs get ENIs (awsvpc). Scaling via:
- Compute Environment: Min/max vCPUs—e.g., 0-100, Spot 70%.
- Queue: Multi-queue priority—e.g.,
urgentgets first resources.
Example: 50 ETL jobs on 20 Spot instances—scales up/down dynamically.
Use Cases and Scenarios
ETL: Process 1 TB S3 data—e.g., 100 jobs, 2 vCPUs each. Simulations: Monte Carlo—e.g., 1,000 Spot tasks. Rendering: Video frames—e.g., 50 Fargate jobs.
Edge Cases and Gotchas
Spot Interruptions: 2-min warning—checkpoint to S3. Queue Backlog: Low priority starves—adjust ratios. Fargate Limits: 16 vCPUs max/task—split big jobs. Startup Lag: EC2 provisioning—pre-warm with min vCPUs.
Integration with Other Services
ECS: Runs tasks—e.g., Fargate jobs. S3: Input/output—e.g., s3://data. CloudWatch: Logs/metrics—e.g., job failures. IAM: Job roles—e.g., DynamoDB access. Step Functions: Orchestrate—e.g., multi-step batch.
Overview
AWS Elastic Beanstalk, launched in 2011, is a Platform-as-a-Service (PaaS) for deploying and managing applications without wrestling with infrastructure. It abstracts EC2, ASG, ELB, and more—upload code (e.g., Java, Python, Node.js), and Beanstalk handles provisioning, scaling, and monitoring. It’s less flexible than ECS or EC2 but faster for devs wanting “just deploy”—think Heroku on AWS, ideal for web apps or APIs.
Architecture and Core Components
Beanstalk is a regional service, orchestrating AWS resources under the hood. Key components:
- Application: Top-level—e.g.,
my-app—holds versions and environments. - Environment: Running instance—e.g.,
prod—EC2, ELB, ASG bundle. - Application Version: Code bundle—e.g.,
v1.0.zip—stored in S3. - Platform: Prebuilt stack—e.g.,
Python 3.9 on Amazon Linux 2.
Deploys to EC2 (single-instance or load-balanced)—e.g., t3.micro cluster in VPC. Managed updates patch OS/apps.
Features and Configuration
Platforms: Java, .NET, Node.js, etc.—e.g., Dockerrun.aws.json for Docker. Env Vars: Config—e.g., DB_HOST. Scaling: ASG rules—e.g., 1-4 instances, CPU > 70%. Limits: 10 apps, 75 versions—soft limits.
Pricing
Free—pay for resources: EC2 ($0.0104/hr t3.micro), ALB ($0.0225/hr), S3 ($0.023/GB). Example: 2 t3.micro, ALB, 24 hrs = $0.76/day. Free tier: 750 hrs/month EC2.
Networking and Scaling
VPC-based—public/private subnets. Scaling via:
- ASG: Auto-scales—e.g., 2-10 instances.
- ALB: Load balances—e.g.,
my-app.elasticbeanstalk.com.
Example: Node.js app scales 1-5 instances, ALB routes—zero config.
Use Cases and Scenarios
Web Apps: Flask API—e.g., app.zip to prod. Prototypes: Quick deploy—e.g., PHP site in 5 mins. Legacy: .NET migration—e.g., IIS on EC2.
Edge Cases and Gotchas
Limited Control: No raw EC2 access—use ECS for flexibility. Updates: Managed patches break customizations—test in dev. Scaling Lag: ASG cooldown—e.g., 300s. Costs: ALB adds $16/month—watch usage.
Integration with Other Services
EC2/ASG: Compute/scaling—e.g., t3.micro cluster. ALB: Traffic—e.g., HTTPS. S3: Code storage—e.g., v1.0.zip. CloudWatch: Logs/metrics—e.g., 5xx alarms. RDS: DB—e.g., MySQL env.
Monitoring and Management Services
Tools for observing, auditing, and managing AWS resources and workloads.
Overview
Amazon CloudWatch, launched in 2009, is AWS’s observability service, collecting, storing, and analyzing metrics, logs, and events from compute resources and beyond. It’s the pulse of your AWS environment, providing real-time insights into performance (via metrics), diagnostics (via logs), and automation (via alarms and events). While it integrates tightly with compute services like EC2, Lambda, and Fargate, its scope spans storage, databases, networking, and even custom apps—making it a central hub for monitoring and managing your cloud infrastructure. CloudWatch isn’t about running workloads but understanding them deeply, from system health to application behavior.
Architecture and Core Components
CloudWatch operates as a distributed, regional service, ingesting data from over 70 AWS services, custom applications, and on-premises systems via APIs or agents. Data is processed, stored, and made queryable, with outputs driving dashboards, alarms, or event-driven actions. Its architecture is serverless—AWS manages the backend, likely a mix of time-series databases (for metrics) and log aggregation systems. Key components include:
- Metrics: Time-series data points—e.g., EC2
CPUUtilization, LambdaInvocations—stored for 15 months with granularity from 1 second to 1 month. - Logs: Unstructured or semi-structured text—e.g., Lambda stdout, Apache logs—organized into Log Groups (e.g.,
/aws/lambda/myFunction) and Streams (per instance/shard). - Events: Real-time triggers—e.g., EC2 state change, S3 upload—routed via Event Rules to targets like Lambda or SNS.
- Alarms: Metric-based thresholds—e.g.,
CPUUtilization > 80% for 5 minutes—triggering SNS notifications or Auto Scaling.
Data flows in via integrations (e.g., Lambda auto-logs), the CloudWatch Agent (for EC2 memory/disk), or SDKs (custom metrics)—stored regionally with no cross-region aggregation unless you build it.
Features and Capabilities
CloudWatch’s versatility comes from its rich feature set, designed to monitor, troubleshoot, and automate:
- Metrics: Predefined from AWS (e.g., S3
BucketSizeBytes) or custom (e.g.,AppLatencyviaPutMetricData)—supports namespaces, dimensions (e.g., per-instance), and stats (avg, max). - Logs Insights: SQL-like queries on logs—e.g.,
fields @timestamp, @message | filter @message like /error/ | sort @timestamp desc—powered by a Presto-based engine for fast analysis. - Dashboards: Custom visualizations—e.g., graph EC2 CPU, Lambda errors, and S3 requests side-by-side—shareable across teams.
- Synthetics: Canary scripts (Node.js/Python) monitor endpoints—e.g., ping
/healthevery 5 minutes, alert on 500s—simulating user behavior. - Events and EventBridge: Rules match patterns (e.g.,
{"source": "aws.ec2"})—trigger Lambda, step functions, or SNS; EventBridge extends with custom buses. - X-Ray Integration: Links traces to metrics—e.g., Lambda latency tied to invocation count—for end-to-end debugging.
Retention: Metrics free for 15 months (1-second data downsampled after 3 hours); logs stored indefinitely (set expiration) or exported to S3 for archival—e.g., 90 days active, then Glacier.
Pricing
CloudWatch’s pricing is pay-as-you-go, tiered by feature:
- Metrics: Free for basic AWS metrics (e.g., EC2 CPU), $0.30/month per custom metric, $0.01/1,000 requests for high-res (1-second).
- Logs: $0.50/GB ingested, $0.03/GB-month stored—free tier 5 GB/month ingest+storage. Insights: $0.005/GB scanned.
- Alarms: $0.10/month (standard, 1-minute), $3/month (high-res, 1-second).
- Dashboards: $3/month per dashboard—first free.
- Synthetics: $0.001/run (10-second interval)—e.g., 5-minute canary = $0.288/day.
- Events: $1/1M events; custom EventBridge higher.
Example: 10 GB logs ingested, 5 custom metrics, 2 alarms = $6.70/month ($5 logs + $1.50 metrics + $0.20 alarms)—costs soar with verbose logging.
Use Cases and Scenarios
CloudWatch powers observability and automation:
- Performance Monitoring: EC2 CPU alarm notifies SNS at 90%—e.g., email ops for manual review.
- Auto-Scaling: Fargate tasks scale on
CPUUtilization > 70%—e.g., 3 to 10 containers dynamically. - Debugging: Query Lambda logs for
timeouterrors—e.g.,fields @timestamp | filter @message like /timeout/—pinpoint failures. - Scheduled Tasks: EventBridge triggers Lambda nightly—e.g., cleanup S3 temp files.
- Health Checks: Synthetics pings
/status—alerts on downtime.
Edge Cases and Gotchas
CloudWatch has quirks to master:
- Granularity Costs: 1-second metrics ($0.01/1,000) vs. free 1-minute—balance precision vs. budget.
- Log Explosion: Chatty apps (e.g., debug enabled) spike ingestion—filter at source (e.g., Lambda log level) or face $50+/month bills.
- No Auto-Delete: Logs persist unless expiration set—e.g., 30-day policy or S3 lifecycle—manual cleanup otherwise.
- Throttling: API limits (e.g., 1M
PutMetricData/month free)—batch writes or request quota increases. - Regional Scope: No native cross-region view—aggregate via custom Lambda or third-party tools.
Integration with Other Services
CloudWatch ties AWS together:
- EC2: Agent (
/opt/aws/amazon-cloudwatch-agent/) sends memory, disk—e.g.,MemoryUtilizationmissing from basic metrics. - Lambda: Auto-logs stdout—e.g.,
print("Error")hits/aws/lambda/myFunction—metrics likeDuration,Errors. - Fargate: Task metrics (CPU, memory)—e.g., scale ECS Service on
MemoryUtilization > 80%. - SNS: Alarm notifications—e.g., SMS on CPU spike; event targets—e.g., notify on S3 upload.
- S3: Export logs—e.g., 90-day retention then Glacier; metrics like
BucketSizeBytes. - X-Ray: Correlate traces—e.g., Lambda cold start latency with
Durationmetric.
Overview
AWS CloudTrail, launched in 2013, is an auditing and governance service that records API calls and account activity—e.g., who created an S3 bucket, when, and from where. It ensures compliance, security, and troubleshooting by logging every action across AWS services. From basics (trail setup) to advanced (multi-region trails, Insights), CloudTrail scales to millions of events/day with tamper-proof storage.
Architecture and Core Components
CloudTrail is a regional service—likely a log aggregator—delivering events to S3 and CloudWatch Logs. Key components:
- Trail: Config—e.g.,
my-trail—captures management, data, or Insights events. - Event: Record—e.g.,
{"eventName": "CreateBucket", "userIdentity": "alice"}—JSON log. - S3 Bucket: Sink—e.g.,
s3://my-trail-logs/—stores events, 11 9’s durability. - Insights: Anomaly—e.g., unusual API spikes—AI-driven detection.
Events flow: AWS API → CloudTrail → S3/Logs—~15m latency—99.9% SLA—tamper detection via digests.
Features and Configuration
Basics: Create—e.g., aws cloudtrail create-trail --name my-trail --s3-bucket-name my-trail-logs—Enable—e.g., aws cloudtrail start-logging—View—e.g., aws cloudtrail lookup-events. Intermediate: Multi-Region—e.g., --is-multi-region-trail—Org—e.g., aws cloudtrail create-trail --is-organization-trail—Data Events—e.g., aws cloudtrail put-event-selectors --data-resources S3—CloudWatch Logs—e.g., aws cloudtrail update-trail --cloud-watch-logs-role-arn .... Advanced: Insights—e.g., aws cloudtrail put-insight-selectors --insight-type ApiCallRateInsight—Encryption—e.g., KMS—Validation—e.g., aws cloudtrail validate-logs—Lake—e.g., aws cloudtrail create-event-data-store—Tags—e756.g., env=prod—Limits: 50 trails, 5 data resources—soft limits.
Pricing
Management Events: Free—1 trail/region—Additional—$2.00/100K events. Data Events: $0.10/100K—Insights—$0.35/100K analyzed—Lake—$0.028/GB ingested, $0.012/GB-month stored—e.g., 1M data events, 1M Insights, 10 GB Lake = $4.28/month. Free tier: 1 trail (management events)—forever. Example: 10M data events, 5M Insights, 100 GB Lake = $54.70/month ($10 + $1.75 + $42.95).
Monitoring and Scaling
Scales with API activity:
- Basic: Management—e.g., IAM changes—1M events/month.
- Intermediate: Data—e.g., S3 puts—10M events/month—Multi-Region—e.g., global audit.
- Advanced: Insights—e.g., 1M anomalies—Lake—e.g., 1 TB queried—100M events/month.
Example: Audit trail—my-trail (10M data events), Insights (spikes), Lake (long-term)—scales to 1B events/month.
Use Cases and Scenarios
Basic: Audit—e.g., who deleted EC2—Security—e.g., IAM changes. Intermediate: Compliance—e.g., PCI logs—Data—e.g., S3 access. Advanced: Insights—e.g., anomaly alerts—Lake—e.g., Athena queries.
Edge Cases and Gotchas
Latency: 15m—e.g., near-real-time—buffer apps—Data Events—e.g., 5 resources max—split trails. Cost: 1B data events—e.g., $1,000/month—limit selectors—Insights—e.g., noisy—tune thresholds. Lake: Query cost—e.g., 1 TB = $28—optimize—Retention—e.g., infinite—S3 lifecycle.
Integration with Other Services
S3: Storage—e.g., s3://logs/—Athena: Query—e.g., Lake tables—CloudWatch: Logs—e.g., real-time—Events—e.g., SNS trigger. Lambda: Process—e.g., parse events—Config: Rules—e.g., compliance check—IAM: Audit—e.g., policy changes.
Overview
AWS Config, launched in 2014, is a configuration management and compliance service that tracks resource changes—e.g., EC2 tags, S3 encryption—over time. It provides a historical view and rule-based evaluations for governance and auditing. From basics (resource tracking) to advanced (multi-account conformance, remediation), Config scales to thousands of resources with continuous monitoring.
Architecture and Core Components
Config is a regional service—likely a state store + event processor—recording snapshots and changes. Key components:
- Resource: Tracked—e.g.,
AWS::EC2::Instance—config history. - Rule: Policy—e.g.,
s3-bucket-public-read-prohibited—compliance check. - Snapshot: State—e.g., JSON of EC2 at T1—stored in S3.
- Aggregator: Multi-account—e.g., Org-wide view—centralized data.
Changes flow: Resource → Config → S3/CloudWatch—real-time via Streams—99.9% SLA—11 9’s durability with S3.
Features and Configuration
Basics: Enable—e.g., aws configservice start-configuration-recorder --recorder-name my-recorder—Track—e.g., aws configservice describe-configuration-recorders—Rule—e.g., aws configservice put-config-rule --config-rule-name my-rule. Intermediate: S3 Delivery—e.g., --delivery-channel S3—History—e.g., aws configservice get-resource-config-history --resource-id i-123—Remediation—e.g., aws configservice put-remediation-configurations --auto-remediate. Advanced: Multi-Account—e.g., aws configservice put-aggregator --aggregator-name my-agg—Conformance—e.g., aws configservice put-conformance-pack --template-s3-uri s3://my-template.yaml—Streams—e.g., aws configservice subscribe-to-resource-changes—Tags—e.g., env=prod—Limits: 100 rules, 50 aggregators—soft limits.
Pricing
Recording: $0.003/resource-month—Rules—$2.00/rule-month—Evaluations—$0.0001/eval—e.g., 100 resources, 10 rules, 1M evals = $32.30/month. Aggregator: Free—Conformance—$0.001/resource-eval—S3—$0.023/GB-month—e.g., 1K resources, 1 GB = $1.02/month. Free tier: None. Example: 1K resources, 50 rules, 10M evals, 1 TB conformance = $1,523/month ($3 + $100 + $1 + $419).
Monitoring and Scaling
Scales with resources:
- Basic: Track—e.g., 10 EC2—Rules—e.g., 5 checks—1K events/month.
- Intermediate: History—e.g., 100 resources—Remediation—e.g., SSM—10K events/month.
- Advanced: Aggregator—e.g., 10 accounts—Conformance—e.g., 1K resources—1M events/month.
Example: Compliance—my-config (1K resources), 50 rules, Org aggregator—scales to 10K resources.
Use Cases and Scenarios
Basic: Inventory—e.g., EC2 list—Compliance—e.g., encryption check. Intermediate: Change—e.g., tag drift—Remediation—e.g., fix S3 ACLs. Advanced: Multi-Account—e.g., Org audit—Conformance—e.g., CIS benchmarks.
Edge Cases and Gotchas
Recording: Delay—e.g., 10m—near-real-time—Unsupported—e.g., some global services—check docs. Rules: Cost—e.g., 1K rules = $2K/month—optimize—Eval—e.g., 1B = $100—limit scope. Conformance: Complexity—e.g., YAML errors—validate—Cost—e.g., 1M resources = $1K—sample audits.
Integration with Other Services
S3: Snapshots—e.g., s3://config/—CloudTrail: Events—e.g., API context—CloudWatch: Metrics—e.g., ConfigRulesCompliance. SSM: Remediation—e.g., AWS-FixS3Encryption—Lambda: Custom—e.g., rule logic—IAM: Audit—e.g., role changes.
Overview
Amazon EventBridge (formerly CloudWatch Events), relaunched in 2019, is a serverless event bus for routing events—e.g., EC2 state changes, custom app events—to targets like Lambda or SNS. It enables event-driven architectures with decoupled systems. From basics (scheduled rules) to advanced (Schema Registry, Archive), EventBridge scales to billions of events/month with low latency.
Architecture and Core Components
EventBridge is a regional, serverless service—likely a pub/sub system—ingesting events via APIs or integrations. Key components:
- Event: Payload—e.g.,
{"source": "aws.ec2", "detail-type": "EC2 Instance State-change"}—JSON. - Rule: Filter—e.g.,
{"source": ["aws.ec2"]}—matches events to targets. - Target: Destination—e.g., Lambda, SQS—processes events.
- Bus: Channel—e.g.,
defaultormy-bus—routes events, custom or partner.
Events flow: Source → Bus → Rule → Target—~100ms latency—99.9% SLA—reliable delivery with retries.
Features and Configuration
Basics: Rule—e.g., aws events put-rule --name my-rule --event-pattern '{"source": ["aws.s3"]}'—Target—e.g., aws events put-targets --rule my-rule --targets Id=1,Arn=arn:aws:lambda:...—List—e.g., aws events list-rules. Intermediate: Schedule—e.g., --schedule-expression "rate(5 minutes)"—Custom—e.g., aws events put-events --entries '{"Source": "my.app"}'—DLQ—e.g., SQS for retries. Advanced: Schema Registry—e.g., aws schemas create-schema --name my-schema—Archive—e.g., aws events create-archive --archive-name my-archive—Replay—e.g., aws events start-replay—Bus—e.g., aws events create-event-bus --name my-bus—Partner—e.g., SaaS events—Encryption—e.g., KMS—Limits: 100 rules/bus, 5 targets/rule—soft limits.
Pricing
Events: $1.00/1M—Custom/Partner—$1.00/1M—Schema—$0.39/1M lookups—Archive—$0.03/GB-month—e.g., 1M events, 1M lookups, 10 GB archive = $2.69/month. Free tier: 100K events—forever (state change only). Example: 10M custom events, 5M lookups, 100 GB archive = $24.95/month ($10 + $1.95 + $13).
Monitoring and Scaling
Scales with event volume:
- Basic: Schedule—e.g., 1K Lambda triggers—AWS—e.g., S3 events—1M/month.
- Intermediate: Custom—e.g., 10M app events—DLQ—e.g., failed retries—10M/month.
- Advanced: Archive—e.g., 1 TB stored—Replay—e.g., 100M reprocessed—Bus—e.g., 1B/month.
Example: Workflow—my-bus (10M custom events), Schema (typed), Archive (replay)—scales to 10B/month.
Use Cases and Scenarios
Basic: Automation—e.g., EC2 stop—Schedule—e.g., nightly job. Intermediate: App—e.g., order events—Retry—e.g., DLQ for failures. Advanced: Schema—e.g., typed events—Archive—e.g., audit replay—Partner—e.g., SaaS integration.
Edge Cases and Gotchas
Latency: 100ms—e.g., not real-time—buffer apps—Throttling—e.g., 10K puts/sec—batch put-events. Cost: 1B events—e.g., $1,000/month—filter wisely—Archive—e.g., 1 PB = $30K—lifecycle to S3. Schema: Overhead—e.g., lookup lag—cache locally—Replay—e.g., 90d limit—plan retention.
Integration with Other Services
Lambda: Target—e.g., process events—S3: Trigger—e.g., uploads—CloudWatch: Metrics—e.g., Invocations. SNS/SQS: Notify—e.g., fan-out—CloudTrail: Audit—e.g., API events—Config: Changes—e.g., resource updates—Step Functions: Orchestrate—e.g., workflows.
Storage Services
Scalable and durable storage solutions for objects, blocks, and file systems in AWS.
Overview
Amazon Simple Storage Service (S3) is an object storage service designed for virtually unlimited scalability, exceptional durability (99.999999999%, or 11 nines), and high availability (99.99% for Standard class). It’s a foundational AWS service, launched in 2006, built to store and retrieve any amount of data at any time, from anywhere on the web. Unlike block storage (e.g., EBS) or file systems (e.g., EFS), S3 uses a flat, key-value structure where data is stored as objects in buckets, identified by unique keys. This simplicity enables use cases ranging from backups and archives to static website hosting (like this page!), big data lakes, and content delivery.
Architecture and Core Components
S3’s architecture is distributed and serverless, abstracting physical infrastructure from users. Data is stored across multiple Availability Zones (AZs) within a region by default, ensuring resilience without user intervention. Here’s how it breaks down:
- Buckets: Top-level containers, analogous to folders but flat in structure. Each bucket has a globally unique name (e.g., "my-bucket-123") and is tied to a region (e.g., us-east-1). Buckets don’t nest; they’re a single namespace across all AWS accounts, hence the uniqueness requirement.
- Objects: The data itself—files, images, etc.—stored with a key (e.g., "photos/vacation.jpg"), metadata (e.g., content-type), and optional tags. Keys can mimic hierarchy with slashes (e.g., "folder/subfolder/file.txt"), but it’s a logical illusion; S3 treats it as one long string.
- Storage Backend: AWS doesn’t disclose specifics, but S3 replicates data across at least three AZs using a distributed system (likely a custom key-value store optimized for durability). Erasure coding and replication ensure data survives hardware failures.
Storage Classes
S3 offers multiple storage classes, each balancing cost, access speed, and durability. Understanding these is critical for cost optimization and performance tuning:
- S3 Standard: Default class for frequent access. 99.99% availability, millisecond latency, $0.023/GB/month (us-east-1). Use for active content like app data or websites.
- S3 Intelligent-Tiering: Auto-moves objects between frequent and infrequent tiers based on access patterns. Adds a small monitoring fee ($0.0025/1,000 objects) but saves manual effort. Ideal for unpredictable workloads.
- S3 Standard-IA (Infrequent Access): Lower cost ($0.0125/GB) with a 30-day minimum storage charge and retrieval fee ($0.01/GB). Suits backups accessed occasionally.
- S3 One Zone-IA: Cheaper ($0.01/GB) but stores in one AZ (99.5% availability), risking data loss if the AZ fails. Use for secondary copies or non-critical data.
- S3 Glacier: Archival storage ($0.004/GB) with retrieval times from minutes to hours. Perfect for compliance data; retrieval costs vary (e.g., $0.02/GB expedited).
- S3 Glacier Deep Archive: Lowest cost ($0.00099/GB), 12-hour retrieval default. For rarely accessed data like legal records; 180-day minimum charge applies.
Data transitions between classes via Lifecycle Policies—e.g., move logs to Glacier after 90 days, then Deep Archive after a year—automating cost savings.
Data Consistency and Access
S3 provides strong read-after-write consistency for PUTs of new objects (you upload, it’s immediately readable). However, updates or deletes (overwrites) are eventually consistent—there’s a brief window (seconds) where an old version might be returned due to replication lag across AZs. This impacts designs needing instant consistency (e.g., avoid S3 for a database’s primary store). Access is via:
- HTTP/HTTPS: RESTful API (GET, PUT, DELETE) or SDKs. URLs like
s3.amazonaws.com/my-bucket/keyor regional endpoints (e.g.,my-bucket.s3.us-east-1.amazonaws.com). - Pre-signed URLs: Temporary access links (e.g., 5-minute expiration) for private objects—great for secure file sharing.
- CLI/UI: AWS CLI (
aws s3 cp) or Console for manual operations.
Security and Access Control
S3 is private by default—new buckets and objects require explicit permissions. Security layers include:
- IAM Policies: User/service-level access (e.g., allow EC2 to read
my-bucket/*). Example:{"Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::my-bucket/*"}. - Bucket Policies: Bucket-wide rules (e.g., public read:
{"Effect": "Allow", "Principal": "*", "Action": "s3:GetObject"}). Can enforce MFA or IP restrictions. - ACLs: Legacy, less granular—object/bucket ownership (e.g., grant write to another account).
- Encryption: Server-side (SSE-S3 AES-256, SSE-KMS for key management, SSE-C for custom keys) or client-side. Mandatory for compliance in regulated industries.
- Block Public Access: Account/bucket-level toggle to prevent accidental exposure—SAA-C03 emphasizes this.
Example: Hosting this site requires a public bucket policy, but sensitive data might use KMS with IAM roles for Lambda access.
Features and Capabilities
S3’s versatility comes from advanced features:
- Versioning: Tracks object changes—e.g., overwrite
file.txt, and prior versions remain accessible via version IDs. Enables recovery from accidental deletes (usex-amz-version-idin GET). - Lifecycle Policies: Automate transitions (e.g., Standard → Glacier after 90 days) or expiration (delete after 365 days). Saves costs on aging data.
- Replication: Cross-Region (CRR) or Same-Region (SRR)—e.g., replicate
us-east-1tous-west-2for disaster recovery. Requires versioning; rules filter by prefix/tags. - Events: Trigger Lambda, SNS, or SQS on actions (e.g.,
s3:ObjectCreated:*)—e.g., resize images on upload. - Transfer Acceleration: Uses CloudFront’s edge locations for faster uploads over long distances—enable via bucket settings.
- Multipart Upload: Splits large files (e.g., 10 GB) into chunks for parallel upload—resumes on failure. API-driven (
Initiate,UploadPart,Complete). - Static Website Hosting: Serve HTML/CSS/JS (like this page) with custom domains via CloudFront. Set
index.htmlas the index document.
Pricing Model
S3’s pay-as-you-go pricing includes:
- Storage: $0.023/GB (Standard), down to $0.00099/GB (Deep Archive). Free tier: 5 GB/month.
- Requests: $0.005/1,000 GETs, $0.0004/1,000 PUTs—costly for high-frequency operations.
- Data Transfer: Free in (upload), $0.09/GB out to internet (after 100 GB free tier). Region-to-region varies (e.g., $0.02/GB us-east-1 to us-west-2).
- Extras: Retrieval fees (e.g., $0.01/GB Standard-IA), Intelligent-Tiering monitoring ($0.0025/1,000 objects).
Example: Hosting 10 GB on Standard costs $0.23/month, but 1M GETs adds $5—optimize with CloudFront caching.
Use Cases and Scenarios
S3’s flexibility shines in real-world applications:
- Static Websites: Host this site—set bucket public, enable hosting, point to
index.html. Add CloudFront for HTTPS and speed. - Data Lakes: Store petabytes of raw data (e.g., logs, IoT streams) with Athena for SQL queries—use prefixes (e.g.,
year=2025/month=03/) for partitioning. - Backup/DR: Replicate critical files across regions with CRR—e.g., nightly snapshots from EC2 to S3, then to
us-west-2. - Content Delivery: Pair with CloudFront—e.g., serve 4K videos with low latency, S3 as origin.
Edge Cases and Gotchas
Deep understanding requires knowing S3’s quirks:
- Eventual Consistency: Overwrites might show old data briefly—use unique keys (e.g., timestamps) for critical updates.
- Request Rate: S3 auto-scales but throttles at ~3,500 PUTs/sec or 5,500 GETs/sec per prefix—spread keys (e.g., hash prefixes) for high throughput.
- Versioning Overhead: Enabled buckets accumulate versions—delete old ones manually or via lifecycle to control costs.
- Cross-Region Latency: CRR isn’t instant (minutes)—not real-time DR.
Integration with Other Services
S3 integrates tightly with AWS:
- Lambda: Process uploads (e.g., thumbnail generation)—S3 event triggers Lambda.
- CloudFront: Cache S3 objects at edge locations—reduces GET costs and latency.
- Athena: Query CSV/JSON in S3 without a database—e.g., analyze logs in
s3://logs/. - Snowball: Physically transfer terabytes to S3—beats slow uploads for migrations.
Overview
Amazon Elastic Block Store (EBS) provides persistent block storage for EC2 instances, acting as virtual hard drives with low-latency access since its launch in 2008. Unlike S3’s object storage or EFS’s file system approach, EBS delivers raw block-level storage—think of it as a SAN (Storage Area Network) in the cloud, optimized for databases, boot volumes, and transactional workloads. It offers durability (99.999% single-region) and flexibility—resize, snapshot, or detach volumes without downtime—making it a cornerstone for compute-intensive applications needing consistent IOPS.
Architecture and Core Components
EBS volumes reside in a single Availability Zone (AZ), replicated within that AZ’s storage fabric for durability—not across AZs (use snapshots for multi-AZ DR). Data is stored in blocks (e.g., 4 KB chunks), attached to EC2 instances over a high-speed network (not local disk), leveraging AWS’s Nitro System for performance. Key components:
- Volumes: Block devices (e.g., 1 GB to 16 TB) attached to one EC2 instance (or multiple with Multi-Attach)—e.g.,
/dev/xvdaas root. - Snapshots: Incremental backups stored in S3—e.g., snapshot a 100 GB volume, only changed blocks since last snapshot are saved.
- Storage Backend: AWS uses SSDs or HDDs (type-dependent), replicated within AZ—erasure coding ensures data survives hardware faults.
Volumes are network-attached via ENIs, with latency in milliseconds—faster than S3, slower than Instance Store.
Volume Types and Performance
EBS offers SSD and HDD volume types, each tuned for specific workloads—balancing IOPS (I/O operations per second), throughput (MB/s), and cost:
- gp3 (General Purpose SSD): 3,000 IOPS base (up to 16,000), 125 MB/s base (up to 1,000), $0.08/GB—default for most apps, cost-effective.
- gp2 (Legacy SSD): 3 IOPS/GB (3,000-16,000), 250 MB/s max, $0.10/GB—older, less flexible than gp3.
- io2 (Provisioned IOPS SSD): Up to 256,000 IOPS, 4,000 MB/s, 99.999% durability, $0.125/GB—high-performance DBs (e.g., Oracle).
- io1 (Legacy PIOPS): Up to 64,000 IOPS, 1,000 MB/s, $0.125/GB—older io2 alternative.
- st1 (Throughput Optimized HDD): 500 MB/s max, 40-500 IOPS, $0.045/GB—big data, logs.
- sc1 (Cold HDD): 250 MB/s max, 12-250 IOPS, $0.015/GB—infrequent access, archives.
Performance scales with size (except io2)—e.g., 1 TB gp3 = 3,000 IOPS base, burst to 16,000. Multi-Attach (io2 only) allows clustering—e.g., shared volume for HA DBs.
Data Management and Access
EBS volumes attach to EC2 via block device mappings—e.g., /dev/sdb—formatted with filesystems (ext4, NTFS). Access is:
- Direct: EC2 mounts volumes—e.g.,
mount /dev/xvdf /data—low-latency reads/writes. - Snapshots: Point-in-time copies in S3—restore to new volumes or share across regions/accounts.
- Encryption: AES-256 via KMS—enabled per volume or snapshot, seamless to EC2.
Snapshots are incremental—first full, then deltas—e.g., 100 GB volume, 10 GB changed = 10 GB stored. Restore lazy-loads data—initial reads slower until fetched from S3.
Security and Access Control
EBS is private to your VPC—security is layered:
- IAM: Controls volume/snapshot actions—e.g.,
{"Action": "ec2:CreateVolume", "Resource": "*"}. - Encryption: KMS keys (default or custom)—e.g.,
aws/ebskey auto-applied, or rotate custom keys. - Snapshot Sharing: Share encrypted snapshots—recipient needs KMS key access.
- Resource Policies: Restrict snapshot access—e.g., specific accounts only.
Example: Encrypt a DB volume with KMS, share snapshot with DR account—secure and compliant.
Features and Capabilities
EBS enhances block storage with advanced features:
- Resize: Increase size/IOPS on-the-fly—e.g., 100 GB gp3 to 200 GB, extend filesystem live.
- Snapshots: Backup/restore—e.g., nightly cron job snapshots to S3, cross-region copy for DR.
- Multi-Attach: io2 volumes shared across instances—e.g., clustered PostgreSQL in one AZ.
- Fast Snapshot Restore (FSR): Pre-warms snapshots—e.g., instant restore for 10 volumes, $0.75/hr per FSR.
- Elastic Volumes: Change type—e.g., gp2 to gp3—minimal downtime.
Pricing Model
EBS pricing varies by type:
- Storage: $0.08-$0.125/GB (SSD), $0.015-$0.045/GB (HDD)—e.g., 100 GB gp3 = $8/month.
- IOPS: io2/io1 $0.065/PIOPS-month—e.g., 10,000 IOPS = $650/month.
- Snapshots: $0.05/GB-month—incremental, e.g., 10 GB changed = $0.50/month.
- FSR: $0.75/hr per snapshot—e.g., 2 FSRs = $36/day.
No free tier—costs tied to EC2 usage. Example: 200 GB gp3 (3,000 IOPS) + 20 GB snapshot = $17/month.
Use Cases and Scenarios
EBS powers persistent workloads:
- Boot Volumes: EC2 root (8 GB gp3)—e.g., Amazon Linux AMI.
- Databases: io2 for MySQL (10,000 IOPS)—e.g., transactional e-commerce DB.
- DR: Snapshots to S3, restore in another region—e.g., nightly backup of 1 TB volume.
- Big Data: st1 for Hadoop—e.g., 5 TB logs with 500 MB/s throughput.
Edge Cases and Gotchas
Single AZ: AZ failure loses volume—snapshot to S3 for DR. Performance: gp3 burst limits—e.g., 16,000 IOPS max, io2 for sustained needs. Snapshot Restore: Lazy-loading slows first access—use FSR for speed. Multi-Attach: Same AZ only—cross-AZ needs app-level sync.
Integration with Other Services
EC2: Primary storage—e.g., root + data volumes. S3: Snapshots stored—e.g., copy to us-west-2. CloudWatch: Metrics (e.g., VolumeReadOps)—alarm on IOPS. Data Lifecycle Manager (DLM): Automate snapshots—e.g., daily at 2 AM.
Overview
Amazon Elastic File System (EFS), launched in 2016, is a fully managed, scalable file storage service designed for shared access across multiple EC2 instances, Lambda functions, or on-premises servers. Unlike EBS’s block storage or S3’s object storage, EFS provides a POSIX-compliant file system (NFSv4), perfect for applications needing a traditional directory structure—think shared configs, content management, or big data workloads. It scales automatically (petabytes), offers high availability (multi-AZ), and simplifies management—no provisioning or capacity planning required.
Architecture and Core Components
EFS is a regional service, storing data across multiple AZs within a region for durability (11 nines) and availability (99.99%). It uses a distributed file system (likely NFS-based) with a control plane managing metadata and a data plane handling file I/O. Key components:
- File Systems: The top-level resource—e.g.,
fs-12345678—tied to a VPC, with mount targets in subnets. - Mount Targets: ENI-based endpoints per AZ—e.g.,
fs-12345678.efs.us-east-1.amazonaws.com—clients connect via NFS. - Data Storage: Elastic—grows/shrinks with usage, no fixed size—e.g., 1 GB to 10 TB seamlessly.
Data replicates across AZs—writes sync immediately (strong consistency), reads are low-latency via regional caching. Access is network-based, requiring VPC connectivity.
Performance Modes and Storage Classes
EFS offers performance tailored to latency and throughput:
- General Purpose: Low-latency (ms), up to 35,000 IOPS—default for web servers, CMS, or dev environments. Use CloudWatch (
BurstCreditBalance) to monitor. - Max I/O: Higher throughput (GB/s), unlimited IOPS—e.g., big data analytics, media processing—sacrifices some latency for scale.
Storage classes optimize cost:
- Standard: Frequent access, $0.30/GB-month—e.g., active files.
- Infrequent Access (IA): $0.025/GB-month, $0.01/GB retrieval—e.g., old logs. Lifecycle policies move files after 30 days.
- One Zone: Single AZ (99.9% availability), $0.16/GB Standard, $0.0133/GB IA—cheaper, less resilient.
Baseline throughput scales with size—e.g., 100 MB/s per TB (burst to 500 MB/s)—Max I/O removes limits.
Data Management and Access
EFS mounts as a filesystem via NFSv4.1—e.g., mount -t nfs4 fs-12345678.efs.us-east-1.amazonaws.com:/ /mnt/efs. Access is:
- EC2: Mount across AZs—e.g., 10 instances share
/data—concurrent reads/writes. - Lambda: Access via VPC—e.g., process files in
/mnt/efs/input. - On-Prem: VPN/Direct Connect—e.g., mount to local servers.
- Backups: AWS Backup—e.g., daily snapshots with 35-day retention.
Strong consistency—writes visible instantly across mounts. Metadata (e.g., permissions) managed via POSIX—e.g., chmod 755.
Security and Access Control
EFS secures data in transit and at rest:
- IAM: Controls API actions—e.g.,
{"Action": "elasticfilesystem:CreateFileSystem"}—plus mount permissions via VPC. - Encryption: AES-256—KMS at rest (default), TLS in transit (enforced).
- Security Groups: Mount target firewall—e.g., allow NFS port 2049 from EC2 subnet.
- POSIX Permissions: File-level access—e.g.,
user1:rw,group2:r.
Example: Encrypt EFS for a shared CMS—EC2 mounts via TLS, IAM restricts creation.
Features and Capabilities
EFS enhances file storage:
- Elastic Scaling: No provisioning—e.g., 1 GB to 1 PB without downtime.
- Lifecycle Management: Move to IA—e.g.,
30-day policysaves 90% on cold data. - Backup: AWS Backup—e.g., incremental daily snapshots to S3.
- Access Points: Restrict mounts—e.g.,
/appsfor app A,/datafor app B—enforce paths/permissions. - Burst Credits: General Purpose bursts to 500 MB/s—credits accrue when idle.
Pricing Model
EFS pricing is usage-based:
- Storage: $0.30/GB-month (Standard), $0.025/GB-month (IA)—One Zone $0.16/$0.0133.
- Requests: Included—e.g., reads/writes free beyond throughput.
- Throughput: Burst free; Provisioned Throughput $6/MB/s-month—e.g., 10 MB/s = $60/month.
- Backup: $0.05/GB-month via AWS Backup.
Example: 100 GB Standard, 10 GB IA = $30.25/month—add $60 for 10 MB/s provisioned. Free tier: 5 GB/month Standard.
Use Cases and Scenarios
EFS excels in shared storage:
- CMS: WordPress on EC2—e.g.,
/wp-contentshared across 5 instances. - Big Data: Spark on Max I/O—e.g., 10 TB datasets, 1 GB/s throughput.
- Dev Environments: Code repos—e.g.,
/gitmounted by 20 devs. - Serverless: Lambda processes
/efs/input—e.g., batch file jobs.
Edge Cases and Gotchas
Burst Limits: General Purpose credits deplete—e.g., 1 TB = 100 MB/s base, burst to 500 MB/s—switch to Max I/O for heavy loads. Latency: Milliseconds—not block-level (EBS)—avoid latency-sensitive DBs. One Zone: AZ failure loses data—use multi-AZ for critical apps. Cost: Expensive vs. S3—e.g., 1 TB = $300/month vs. $23.
Integration with Other Services
EC2: Multi-mount—e.g., /data across AZs. Lambda: File processing—e.g., read /efs/logs. Fargate: Persistent storage—e.g., ECS tasks share /configs. CloudWatch: Metrics (e.g., DataReadBytes)—alarm on credit depletion. AWS Backup: Snapshots—e.g., nightly to S3.
Overview
Amazon FSx for Lustre, introduced in 2018, is a fully managed, high-performance file storage service built on the open-source Lustre filesystem, optimized for fast, parallel access to large datasets. Unlike FSx for Windows (SMB-based) or EFS (general-purpose NFS), FSx for Lustre targets high-performance computing (HPC), machine learning (ML), and big data workloads needing massive throughput (100s of GB/s) and low latency (sub-millisecond). It integrates tightly with S3, enabling seamless data movement—e.g., process petabytes from S3, write results back—making it a powerhouse for compute-intensive, temporary storage needs.
Architecture and Core Components
FSx for Lustre runs in a single region, with data stored in one AZ (Persistent) or ephemeral (Scratch) configurations. It leverages Lustre’s distributed architecture—splitting metadata (MDS) and data (OSTs) across servers for parallelism. Key components:
- File Systems: The Lustre instance—e.g.,
fs-abcdef12—with a capacity (1.2 TB-100s of TB). - Mount Targets: VPC endpoints—e.g.,
fs-abcdef12.fsx.us-east-1.amazonaws.com—clients mount via Lustre protocol. - Storage Backend: SSD-based, optimized for IOPS and throughput—replicated within AZ (Persistent) or not (Scratch).
Data syncs with S3 optionally—e.g., import on creation, export on demand. Access is VPC-only, via ENIs.
Performance and Storage Options
FSx for Lustre offers two deployment types:
- Scratch: Max performance (200 MB/s/TB base, burst to GB/s), no replication—e.g., ML training, temporary data. Data lost on failure.
- Persistent: Durable (11 nines), 50-200 MB/s/TB base—e.g., long-running HPC. HA option with standby in another AZ (failover in minutes).
Throughput scales with size—e.g., 6 TB = 1.2 GB/s base (Scratch)—IOPS up to 100,000s. Lustre stripes data across OSTs—e.g., 1 MB stripe size for large files.
Data Management and Access
Mount via Lustre client—e.g., mount -t lustre fs-abcdef12@tcp:/fsx /mnt/lustre on EC2. Access is:
- EC2: Parallel mounts—e.g., 100 instances read
/mnt/lustre/dataat GB/s. - S3 Integration: Link to bucket—e.g.,
aws fsx update-data-repository-association—import/export files. - Backups: Persistent only—daily, 0-35 days retention—e.g., restore to new FS.
POSIX-compliant—e.g., ls -l works—strong consistency across clients.
Security and Access Control
FSx for Lustre secures via:
- IAM: API control—e.g.,
{"Action": "fsx:CreateFileSystem"}. - Encryption: KMS at rest (default), in transit—e.g., Lustre client encrypts.
- Security Groups: VPC firewall—e.g., allow Lustre ports (988, 1018-1023).
- POSIX Permissions: File-level—e.g.,
chmod 644—no AD integration.
Example: Encrypt ML dataset—EC2 mounts via VPC, IAM restricts access.
Features and Capabilities
S3 Sync: Bidirectional—e.g., datarepo link imports S3 bucket, exports results. HA: Persistent multi-AZ—e.g., failover in 10s of seconds. Backups: Persistent only—e.g., PITR from yesterday. Striping: Customizable—e.g., 4 OSTs for 4 GB/s reads.
Pricing Model
Storage: $0.14/GB-month (Persistent), $0.0133/GB-month (Scratch)—e.g., 6 TB Persistent = $840/month. Throughput: Included—e.g., 1.2 GB/s free at 6 TB. Backups: $0.05/GB-month—e.g., 1 TB = $50/month. S3 Requests: Standard S3 rates—e.g., $0.005/1,000 GETs.
Use Cases and Scenarios
ML Training: 10 TB dataset—e.g., 100 EC2 GPUs read at 2 GB/s, export to S3. HPC: Simulations—e.g., 1 PB Scratch for weather modeling. Media Processing: 4K rendering—e.g., 50 TB Persistent, HA.
Edge Cases and Gotchas
Scratch Risk: No durability—save to S3 often. Cost: High for persistence—e.g., 10 TB = $1,400/month vs. S3 $230. Single AZ (Scratch): Failure loses data—use Persistent for critical. S3 Sync Latency: Minutes, not real-time—plan workflows.
Integration with Other Services
EC2: HPC clusters—e.g., /mnt/lustre. S3: Data lake—e.g., import s3://data, export results. CloudWatch: Metrics (e.g., FreeDataStorageCapacity)—alarm on space. Fargate/EKS: Mount for containerized ML—e.g., /lustre/input.
Overview
Amazon FSx for Windows File Server, launched in 2018, is a fully managed Windows-based file storage service, delivering SMB (Server Message Block) file shares for Windows-centric workloads. Unlike EFS’s POSIX focus or S3’s object model, FSx supports NTFS, Active Directory (AD) integration, and Windows permissions—ideal for enterprise apps like SQL Server, IIS, or file shares needing Windows compatibility. It offers HA (multi-AZ), backups, and encryption, abstracting the complexity of managing Windows file servers.
Architecture and Core Components
FSx runs on AWS’s infrastructure, emulating a Windows Server with SMB (2.0-3.1.1). Data is stored in a single region, with options for single-AZ or multi-AZ deployments:
- File Systems: The storage unit—e.g.,
fs-98765432—with a capacity (8 GB-100 TB) and throughput. - File Shares: SMB endpoints—e.g.,
\\fs-98765432.file.fsx.us-east-1.amazonaws.com\share—mounted by clients. - Storage Backend: SSD or HDD, replicated within/between AZs—e.g., multi-AZ syncs primary to standby.
Data is durable (11 nines)—multi-AZ uses synchronous replication; single-AZ relies on AZ-internal redundancy. Access requires VPC and AD (AWS Managed AD or on-prem).
Performance and Storage Options
FSx performance scales with size and type:
- SSD: Low-latency, 12-2,048 MB/s, $0.13/GB-month—e.g., app data, DBs.
- HDD: Higher capacity, 12-80 MB/s, $0.013/GB-month—e.g., backups, archives.
Throughput: 8 MB/s base per TB (SSD), burst to 2,048 MB/s—provisioned option (e.g., 512 MB/s) for high demand. IOPS scale automatically—e.g., 3 IOPS/GB for SSD.
Data Management and Access
FSx mounts via SMB—e.g., net use Z: \\fs-98765432\share on Windows. Access is:
- EC2: Windows instances mount shares—e.g.,
Z:\datafor IIS. - On-Prem: VPN/Direct Connect—e.g., AD-joined servers access.
- Backups: Daily automatic—e.g., 7-day retention, PITR (point-in-time recovery).
- Data Deduplication: Reduces redundancy—e.g., save 30% on repetitive files.
NTFS permissions—e.g., Administrators:Full, Users:Read—managed via AD. Strong consistency across mounts.
Security and Access Control
FSx integrates with Windows security:
- AD: Required—AWS Managed AD or on-prem—e.g.,
corp.example.comusers/groups. - Encryption: KMS at rest, SMB encryption in transit—e.g., SMB 3.0+ enforces.
- IAM: API access—e.g.,
{"Action": "fsx:CreateFileSystem"}. - Security Groups: VPC firewall—e.g., allow SMB ports 445, 135-139.
- ACLs: NTFS-level—e.g.,
user1:rw, inherited from parent.
Example: AD-joined EC2 mounts encrypted share—only Domain Users access.
Features and Capabilities
FSx enhances Windows storage:
- Multi-AZ: HA—e.g., failover in 60s, 99.99% availability.
- Backups: Automated or manual—e.g., 35-day retention, restore to new FS.
- Deduplication: Enabled per share—e.g., compress repetitive docs.
- Shadow Copies: Previous versions—e.g., recover deleted files from 2 PM snapshot.
- Quota Management: Per-user limits—e.g., 10 GB/user.
Pricing Model
FSx pricing includes:
- Storage: $0.13/GB-month (SSD), $0.013/GB-month (HDD)—e.g., 1 TB SSD = $130/month.
- Throughput: $2.20/MB/s-month provisioned—e.g., 512 MB/s = $1,126/month.
- Backups: $0.05/GB-month—e.g., 100 GB = $5/month.
- Requests: Free—e.g., SMB reads/writes included.
Example: 1 TB SSD, 64 MB/s, 50 GB backup = $162.50/month ($130 + $30 + $2.50)—no free tier.
Use Cases and Scenarios
FSx powers Windows workloads:
- File Shares: AD-integrated storage—e.g.,
\\fsx\deptfor 100 users. - SQL Server: Persistent storage—e.g., 2 TB SSD for DB files.
- IIS: Web content—e.g.,
Z:\wwwrootacross 5 instances. - DR: Multi-AZ + backups—e.g., failover + restore in us-east-1b.
Edge Cases and Gotchas
AD Dependency: No AD, no access—setup required. Cost: High vs. EFS—e.g., 1 TB SSD = $130 vs. $300 for EFS. Multi-AZ Failover: 60s delay—plan app tolerance. Throughput: Base scales slowly—provision for peaks.
Integration with Other Services
EC2: Windows mounts—e.g., Z:\data. AWS Managed AD: Authentication—e.g., corp.example.com. CloudWatch: Metrics (e.g., DataReadBytes)—alarm on usage. Backup: Snapshots—e.g., daily to S3. VPC: Private access—e.g., no IGW needed.
Networking Services
AWS networking solutions for connectivity, traffic management, and global content delivery.
Overview
Amazon Virtual Private Cloud (VPC), launched in 2009, is AWS’s core networking service, providing a logically isolated virtual network within the AWS cloud. It’s the foundation for most AWS services—EC2, RDS, Lambda—letting you define IP ranges, subnets, routing, and connectivity. Think of it as your private data center: control access, segment resources, and connect to on-premises or other clouds. From basics (public/private subnets) to advanced (VPC Peering, Transit Gateway), it’s flexible for simple apps or complex enterprises.
Architecture and Core Components
VPC is a regional construct, spanning AZs within a region (e.g., us-east-1). It’s built on AWS’s global network, isolating your resources via virtualization. Key components:
- VPC: The network—e.g.,
10.0.0.0/16(65,536 IPs)—regional scope. - Subnets: AZ-specific segments—e.g.,
10.0.1.0/24(256 IPs)—public (Internet access) or private (isolated). - Route Tables: Traffic rules—e.g.,
0.0.0.0/0to Internet Gateway (IGW)—one per subnet. - Internet Gateway (IGW): Public access—e.g., connects VPC to internet.
- NAT Gateway: Private subnet outbound—e.g.,
nat-123in public subnet, $0.045/hr. - Network ACLs (NACLs): Stateless firewall—e.g., allow port 80 inbound—subnet-level.
- Security Groups: Stateful firewall—e.g., allow SSH from 10.0.0.5—instance-level.
Data flows via AWS’s private backbone—e.g., EC2 in 10.0.1.0/24 to RDS in 10.0.2.0/24—no public internet unless routed via IGW/NAT. Default VPC per region—e.g., 172.31.0.0/16—preconfigured for quick starts.
Features and Configuration
CIDR: Primary—e.g., 10.0.0.0/16—secondary added—e.g., 192.168.0.0/16. Subnets: /28 (16 IPs) to /16—e.g., 10.0.1.0/24 per AZ. Routing: Custom tables—e.g., 10.1.0.0/16 to VPC Peering. Gateways: IGW (free), NAT (HA in AZ)—e.g., $32/month. VPC Peering: Connect VPCs—e.g., us-east-1 to us-west-2, no transitive routing. Transit Gateway: Hub-and-spoke—e.g., 10 VPCs + on-prem, $0.02/GB. Endpoints: Private AWS access—e.g., vpce-s3, $0.01/hr. Limits: 5 VPCs, 200 subnets—soft limits.
Pricing
VPC: Free—core networking costs nothing. NAT Gateway: $0.045/hr + $0.045/GB—e.g., 10 GB/day = $32.40/month. VPC Peering: $0.01/GB (inter-region)—e.g., 100 GB = $1. Transit Gateway: $0.02/GB + $0.05/attachment-hr—e.g., 5 VPCs, 50 GB = $75/month. Endpoints: $0.01/hr + $0.01/GB—e.g., S3 access = $7.30/month. Free tier: None—NAT/Transit adds up.
Networking and Scaling
VPC scales with AWS—millions of IPs. Basics to advanced:
- Basic: Public subnet—e.g., EC2 + IGW,
10.0.1.0/24—private subnet—e.g., RDS,10.0.2.0/24. - Intermediate: NAT for outbound—e.g., private EC2 to S3—NACLs—e.g., block 22, allow 80.
- Advanced: Peering—e.g.,
10.0.0.0/16to10.1.0.0/16—Transit Gateway—e.g., hub to 20 VPCs—Endpoints—e.g., private Lambda to DynamoDB.
Example: 3-tier app—public 10.0.1.0/24 (ALB), private 10.0.2.0/24 (EC2), 10.0.3.0/24 (RDS)—peered to DR VPC.
Use Cases and Scenarios
Basic: Single VPC—e.g., web app, public EC2, private RDS. Hybrid: Direct Connect—e.g., on-prem to VPC. Multi-Tenant: Peering—e.g., dev/test/prod VPCs. Enterprise: Transit Gateway—e.g., 50 VPCs + VPN.
Edge Cases and Gotchas
CIDR Overlap: 10.0.0.0/16 in 2 VPCs—no peering—plan unique ranges. Subnet Size: /28 (5 usable IPs)—e.g., ENI limits cap scaling. NAT Cost: $1/day/AZ—multi-AZ = $90/month—use Endpoints ($7/month). Peering Limits: No transitive routing—e.g., VPC A-B, B-C ≠ A-C—use Transit Gateway. Default VPC: Public by default—secure it.
Integration with Other Services
EC2: Instances in subnets—e.g., 10.0.1.5. RDS: Private DB—e.g., 10.0.2.10. ALB/NLB: Public/private—e.g., route to 10.0.1.0/24. Lambda: VPC access—e.g., ENI in 10.0.3.0/24. S3: Endpoints—e.g., private downloads. CloudWatch: Logs—e.g., VPC Flow Logs, $0.50/GB.
Overview
Elastic Load Balancer (ELB), introduced in 2009, is AWS’s managed load balancing service, distributing traffic across compute targets (EC2, Fargate, Lambda) for scalability and HA. It offers four types: Application Load Balancer (ALB, Layer 7), Network Load Balancer (NLB, Layer 4), Gateway Load Balancer (GLB, Layer 3), and Classic Load Balancer (CLB, legacy). From basic HTTP balancing to advanced IP routing, ELB integrates with VPCs, auto-scales, and offloads traffic management.
Architecture and Core Components
ELB operates in a VPC, leveraging AWS’s edge and regional network—distributed nodes across AZs. Key components:
- Load Balancer: Entry—e.g.,
my-elb-123.us-east-1.elb.amazonaws.com—public or internal. - Listeners: Protocol/port—e.g., HTTP:80—route to targets.
- Target Groups: Endpoints—e.g., EC2, IPs—health-checked (except GLB).
ALB uses reverse proxies (Layer 7), NLB/GLB route packets (Layer 4/3), CLB mixes both—deployed in subnets, cross-zone optional.
ELB Variants and Configuration
ALB: HTTP/HTTPS—path (/api), host (api.example.com), WebSockets, Lambda targets—e.g., 100 rules/listener. NLB: TCP/UDP—static IPs, low latency (100µs), TLS—e.g., 200 targets/group. GLB: IP—GENEVE to appliances (e.g., firewalls)—e.g., no health checks. CLB: Legacy—HTTP/TCP—e.g., basic 100 targets. Features: ALB—sticky sessions; NLB—source IP preservation; GLB—transparent routing; CLB—SSL offload. Limits: ALB 1,000 targets—soft limit.
Pricing
ALB: $0.0225/hr + $0.008/LCU-hr—e.g., 10 LCUs, 24 hrs = $0.78/day. NLB: $0.0225/hr + $0.006/NCU-hr—e.g., 5 NCUs = $0.54/day. GLB: $0.025/hr + $0.007/GCU-hr—e.g., 5 GCUs = $0.58/day. CLB: $0.025/hr + $0.008/GB—e.g., 10 GB = $0.68/day. Free tier: 750 hrs/month. Data out: $0.09/GB.
Networking and Scaling
VPC-based—public (IGW) or private subnets. Scaling:
- Basic: ALB—HTTP to EC2—e.g., 2 instances.
- Intermediate: NLB—TCP to Fargate—e.g., static IP for RDS proxy.
- Advanced: GLB—IP to NGFW—e.g., VPC traffic inspection—ALB + Lambda—e.g., serverless routing.
Example: ALB (/web to 5 EC2), NLB (TCP:3306 to RDS)—auto-scales to 10M requests/sec.
Use Cases and Scenarios
ALB: Microservices—e.g., /api to ECS. NLB: Gaming—e.g., UDP to EC2. GLB: Security—e.g., firewall in VPC. CLB: Legacy—e.g., old HTTP app.
Edge Cases and Gotchas
ALB: 100-rule limit—split complex apps. NLB: Static IP cost—Elastic IP fees if detached. GLB: Appliance failover—manual. CLB: No WebSockets—migrate to ALB. Cross-Zone: $0.01/GB AZ-to-AZ—disable if local.
Integration with Other Services
EC2/ASG: Targets—e.g., scale 2-10. ECS/Fargate: ALB/NLB—e.g., /users. Lambda: ALB—e.g., REST proxy. CloudWatch: Metrics—e.g., RequestCount. ACM: SSL—e.g., TLS 1.3. WAF: ALB—e.g., block XSS.
Overview
Amazon Route 53, launched in 2010, is a scalable, highly available DNS service, managing domain names and routing traffic to AWS resources (ELB, S3) or external endpoints. Beyond basic DNS (A, CNAME), it offers advanced routing—latency-based, geolocation, failover—plus domain registration and health checks. It’s global, leveraging AWS’s edge locations, ideal for websites, APIs, or hybrid setups needing reliable name resolution.
Architecture and Core Components
Route 53 is a global service, using a distributed network of authoritative DNS servers across AWS’s 100+ edge locations. Key components:
- Hosted Zone: DNS namespace—e.g.,
example.com—public or private (VPC). - Records: DNS entries—e.g.,
www A 10.0.1.5—A, CNAME, MX, etc. - Routing Policies: Rules—e.g., latency to
us-east-1ALB—simple, weighted, geo, etc. - Health Checks: Monitor—e.g., HTTP 200 on
/health—failover trigger.
Queries resolve via anycast—e.g., client in London hits nearest edge—100% SLA, no single point of failure.
Features and Configuration
Records: A, AAAA, CNAME, TXT—e.g., api A 10.0.1.5. Policies: Simple—e.g., single ELB; Weighted—e.g., 70% us-east-1, 30% us-west-2; Latency—e.g., fastest region; Geo—e.g., EU to eu-west-1; Failover—e.g., primary to secondary. Private DNS: VPC—e.g., db.local. Domain Registration: $12/year .com. Health Checks: 30s interval—e.g., $0.50/month. Limits: 500 zones, 10,000 records—soft limits.
Pricing
Hosted Zone: $0.50/month—e.g., example.com. Queries: $0.40/1M standard, $0.60/1M latency/geo—e.g., 10M queries = $4. Health Checks: $0.50/month basic, $0.75/month CloudWatch—e.g., 5 checks = $2.50/month. Domain: $12/year .com. Free tier: None—starts at $0.50/month.
Networking and Scaling
Global—no VPC tie-in (except private zones). Scaling:
- Basic: A record—e.g.,
wwwto ALB. - Intermediate: Weighted—e.g., 50/50 split ELBs—Failover—e.g., ALB to S3 static.
- Advanced: Latency—e.g., us-east-1 vs. ap-southeast-1—Geo—e.g., US-only traffic—Multi-value—e.g., 5 IPs for resilience.
Example: api.example.com—latency to 3 ALBs (us, eu, ap), failover to S3.
Use Cases and Scenarios
Basic: Website—e.g., www to S3. HA: Failover—e.g., ELB to DR ELB. Global: Latency—e.g., nearest CDN. Compliance: Geo—e.g., EU data in eu-west-1.
Edge Cases and Gotchas
TTL: 60s default—e.g., slow failover—set to 10s. Health Check Cost: 100 checks = $50/month—optimize. Private DNS: VPC only—no external access. Geo Limits: Continent-level—e.g., no city granularity.
Integration with Other Services
ALB/NLB: DNS target—e.g., api to ELB. S3: Static site—e.g., www. CloudFront: CDN—e.g., cdn.example.com. CloudWatch: Health metrics—e.g., alarm on failures. VPC: Private DNS—e.g., rds.local. ACM: Certs—e.g., HTTPS validation.
Overview
Amazon CloudFront, launched in 2008, is a global Content Delivery Network (CDN) that accelerates content delivery—web pages, videos, APIs—by caching at edge locations worldwide. It reduces latency, offloads origin servers (S3, ELB), and enhances security (DDoS protection, TLS). From basics (caching static S3 files) to advanced (Lambda@Edge, dynamic content), CloudFront scales effortlessly, serving millions of requests/sec across 300+ edge locations as of March 2025.
Architecture and Core Components
CloudFront is a distributed system leveraging AWS’s global network of edge locations—data centers in 90+ cities. Key components:
- Distribution: Configuration—e.g.,
d123456789.cloudfront.net—ties origins to behaviors. - Origin: Source—e.g., S3 bucket
my-site, ELBmy-app—fetches uncached content. - Edge Location: Cache point—e.g., London POP—stores content close to users.
- Behavior: Rules—e.g.,
/images/*caches 24h—path-based routing. - Regional Edge Cache: Mid-tier—e.g., us-east-1—larger, less frequent objects (videos).
Request flow: User → nearest edge (DNS anycast) → cache hit (serve) or miss (fetch origin) → response. Integrates with Shield (DDoS) and WAF (web firewall)—e.g., 99.99% uptime SLA.
Features and Configuration
Basics: Static caching—e.g., S3 origin my-site.s3.amazonaws.com, TTL 24h—HTTPS—e.g., ACM cert *.example.com. Intermediate: Behaviors—e.g., /api/* no cache, /static/* 1 year—Geo-restriction—e.g., block US—Custom domain—e.g., cdn.example.com via Route 53. Advanced: Lambda@Edge—e.g., viewer-request rewrites /old to /new—Field-Level Encryption—e.g., encrypt SSN at edge—Origin Shield—e.g., mid-tier cache in us-west-2—Real-Time Logs—e.g., S3 cloudfront-logs/. Config: Cache policies—e.g., Managed-CachingOptimized—Origins—HTTP/HTTPS, S3 signed URLs. Limits: 25 behaviors, 200 cache policies—soft limits.
Pricing
Data Out: $0.085/GB (US)—e.g., 1 TB = $85—tiered lower (e.g., $0.02/GB at 5 PB). Requests: $0.0075/10K HTTP, $0.01/10K HTTPS—e.g., 1M HTTPS = $1. Invalidations: $0.005/path after 1,000 free—e.g., 100 paths = $0.50. Extras: Lambda@Edge—$0.60/1M—Field Encryption—$0.02/10K—Origin Shield—$0.025/hr. Free tier: 1 TB out, 10M requests/month—forever. Example: 100 GB out, 1M HTTPS, 10 Lambda@Edge = $9.10 ($8.50 + $0.01 + $0.60).
Networking and Scaling
Global—scales to millions of requests:
- Basic: S3 static—e.g.,
images/logo.pngcached 24h—100 users. - Intermediate: ELB—e.g.,
/appcached 1h—Geo—e.g., EU-only—10K users. - Advanced: Lambda@Edge—e.g., A/B test headers—Origin Shield—e.g., 90% hit ratio—1M users, 10 Gbps.
Example: Video site—/static/* (S3, 1 year TTL), /api/* (ELB, no cache), Lambda@Edge for auth—scales to 100M requests/day.
Use Cases and Scenarios
Basic: Website—e.g., S3 HTML cached. Media: Video—e.g., /videos/*.mp4 via regional cache. API: ELB—e.g., /api/v1 with 5s TTL. Dynamic: Lambda@Edge—e.g., personalize content—Geo—e.g., region-specific pages.
Edge Cases and Gotchas
Cache Misses: High TTL—e.g., 1 year—stale content—use invalidations ($0.005/path). Cost: 10 TB out—e.g., $850/month—optimize TTLs. Lambda@Edge: 128 MB limit—e.g., no heavy libs—1s timeout—e.g., slow code fails. Geo: IP-based—e.g., VPN bypass—CloudFront IP ranges shift—update WAF. Origin Failure: No failover—e.g., S3 down = 5xx—add backup origin.
Integration with Other Services
S3: Origin—e.g., my-site.s3.amazonaws.com. ELB: Dynamic—e.g., /app. Route 53: DNS—e.g., cdn.example.com. Lambda@Edge: Logic—e.g., viewer-response adds headers. WAF: Security—e.g., block SQL injection—$5/month. Shield: DDoS—e.g., standard free, advanced $3,000/month. CloudWatch: Metrics—e.g., CacheHitRate, alarm on 50%.
Overview
AWS Global Accelerator, launched in 2018, is a network-layer service that improves performance and availability by routing user traffic to the nearest AWS endpoint (e.g., ELB, EC2) via AWS’s global backbone. Unlike CloudFront’s content caching, it focuses on low-latency, non-cacheable traffic (e.g., gaming, VoIP) using static anycast IPs. From basics (single-region routing) to advanced (multi-region HA, custom weights), it’s built for real-time apps needing global reach.
Architecture and Core Components
Global Accelerator leverages AWS’s private network—300+ edge locations—bypassing public internet congestion. Key components:
- Accelerator: Entry—e.g.,
a123456789.awsglobalaccelerator.com—assigns 2 static IPs. - Listener: Protocol/port—e.g., TCP:80—routes to endpoint groups.
- Endpoint Group: Region-specific—e.g., us-east-1—contains endpoints (ELB, EC2, EIP).
- Endpoint: Target—e.g.,
my-elb.us-east-1.elb.amazonaws.com—weighted for traffic.
Flow: User → static IP (anycast) → nearest edge → AWS backbone → endpoint (e.g., ELB). Health checks—e.g., TCP 200ms—ensure failover—99.99% SLA.
Features and Configuration
Basics: Single region—e.g., TCP:80 to ELB—Static IPs—e.g., 52.1.2.3, 52.4.5.6. Intermediate: Multi-region—e.g., us-east-1 (50%), us-west-2 (50%)—Health checks—e.g., /health, 10s interval—Client IP preservation—e.g., original IP to ELB. Advanced: Custom routing—e.g., 75% us-east-1, 25% eu-west-1—Flow control—e.g., TCP options tuning—DDoS protection—e.g., Shield Standard free. Config: Protocols—TCP/UDP—Ports—e.g., 443, 3478 (STUN). Limits: 20 accelerators, 100 endpoints—soft limits.
Pricing
Accelerator: $0.025/hr—e.g., 1 accelerator = $18/month. Data Transfer: $0.015/GB (US)—e.g., 1 TB = $15—premium routing, varies by region (e.g., $0.08/GB Asia). Free tier: None—starts at $18/month. Example: 1 accelerator, 500 GB us-east-1 = $25.50/month ($18 + $7.50). Note: Endpoint costs separate—e.g., ELB $0.0225/hr.
Networking and Scaling
Global—scales to millions of connections:
- Basic: TCP:80 to ELB—e.g., 1 region, 1K users—static IP.
- Intermediate: Multi-region—e.g., 50/50 us-east-1/eu-west-1—10K users, failover.
- Advanced: UDP—e.g., gaming to EC2, 90% us-east-1—Flow control—e.g., 100K users, 5 Gbps.
Example: VoIP app—TCP:5060 to ELBs (us-east-1 70%, ap-southeast-1 30%)—scales to 1M connections, 50ms latency drop.
Use Cases and Scenarios
Basic: Web app—e.g., ELB HA with static IP. Gaming: UDP—e.g., EC2 game servers, low latency. VoIP: TCP—e.g., SIP to Fargate. Multi-Region: DR—e.g., 90% primary, 10% backup—Global—e.g., nearest endpoint routing.
Edge Cases and Gotchas
Failover: 30-60s—e.g., health check delay—tune interval (10s min). Cost: 10 TB—e.g., $150/month—cheaper than VPN ($0.05/hr) for small loads. Static IPs: No custom domain direct—e.g., Route 53 CNAME needed—2 IPs limit—e.g., no 3rd for redundancy. UDP Limits: No session stickiness—e.g., gaming reconnects—app-level handling. Shield: Standard free—advanced $3,000/month—DDoS spikes need planning.
Integration with Other Services
ELB: Endpoint—e.g., NLB for TCP. EC2: Direct—e.g., UDP to instances. Route 53: DNS—e.g., app.example.com to a123.... Shield: DDoS—e.g., edge protection. CloudWatch: Metrics—e.g., BytesIn, alarm on 80% traffic. IAM: Access—e.g., {"Action": "globalaccelerator:CreateAccelerator"}.
Overview
AWS Direct Connect, launched in 2011, provides a dedicated, private network connection from on-premises to AWS, bypassing the public internet for lower latency, consistent bandwidth, and security. It’s ideal for hybrid workloads—e.g., data migration, DR, or latency-sensitive apps—offering 1 Gbps to 100 Gbps links. From basic single connections to advanced multi-site setups, it integrates VPCs with your data center.
Architecture and Core Components
Direct Connect links your router to an AWS Direct Connect Location (e.g., Equinix DC) via a partner or AWS port. Key components:
- Connection: Physical link—e.g., 1 Gbps fiber—customer to AWS port.
- Virtual Interface (VIF): Logical—e.g., Public (AWS services), Private (VPC), Transit (Transit Gateway)—VLAN-based.
- Direct Connect Gateway: Multi-VPC/region—e.g., 10 VPCs across us-east-1, us-west-2.
- Location: AWS partner site—e.g., NY Equinix—connects to AWS backbone.
Data flows privately—e.g., 10.0.1.0/24 VPC to 192.168.1.0/24 on-prem—BGP for routing, 99.99% SLA per link.
Features and Configuration
Speeds: 1, 10, 100 Gbps (dedicated), 50 Mbps-10 Gbps (hosted via partner)—e.g., 10 Gbps link. VIFs: Public—e.g., S3 access; Private—e.g., VPC 10.0.0.0/16; Transit—e.g., multi-VPC. BGP: Dynamic routing—e.g., ASNs for peering. LAG: Link Aggregation—e.g., 2x10 Gbps = 20 Gbps. Encryption: Optional MACsec (100 Gbps)—e.g., hardware-level security. Limits: 50 VIFs/connection—soft limit.
Pricing
Port: $0.30/hr 1 Gbps, $2.25/hr 10 Gbps, $22/hr 100 Gbps—e.g., 10 Gbps = $1,620/month. Data Out: $0.02/GB (us-east-1)—e.g., 1 TB = $20. Partner: Extra—e.g., $0.03/GB via Equinix. LAG/VIF: Free—e.g., 5 VIFs no charge. Example: 10 Gbps, 2 TB out = $1,660/month ($1,620 + $40).
Networking and Scaling
Hybrid focus—scales with links:
- Basic: 1 Gbps—e.g., on-prem to VPC
10.0.0.0/16—Private VIF. - Intermediate: Public VIF—e.g., S3 at 500 Mbps—LAG—e.g., 2x1 Gbps.
- Advanced: Direct Connect Gateway—e.g., 5 VPCs, 3 regions—100 Gbps—e.g., 50 Gbps traffic.
Example: HQ to 3 VPCs—10 Gbps, Private VIFs via Direct Connect Gateway.
Use Cases and Scenarios
Migration: 10 TB to S3—e.g., 1 Gbps link. DR: VPC sync—e.g., 5 Gbps to us-west-2. Low Latency: Trading—e.g., 100 Gbps to EC2. Hybrid: AD integration—e.g., on-prem to VPC.
Edge Cases and Gotchas
Setup Time: Days—e.g., physical link provisioning—not instant. Cost: $1,000s/month—e.g., 100 Gbps = $16K—VPN cheaper ($0.05/hr). BGP Failure: Manual failover—e.g., no auto-redundancy—dual links needed. Data In: Free—outbound pricey—e.g., $200 for 10 TB.
Integration with Other Services
VPC: Private VIF—e.g., 10.0.1.0/24. S3: Public VIF—e.g., bulk transfer. Transit Gateway: Multi-VPC—e.g., 5 regions. CloudWatch: Metrics—e.g., ConnectionState. EC2: Hybrid apps—e.g., on-prem to instances. VPN: Backup—e.g., over Direct Connect.
Database Services
AWS database solutions for relational, NoSQL, caching, graph, ledger, and time-series workloads.
Overview
Amazon Relational Database Service (RDS), launched in 2009, is a managed service for traditional relational databases, supporting engines like MySQL, PostgreSQL, Oracle, and SQL Server. It simplifies provisioning, scaling, patching, and backups, making it ideal for structured data workloads—e.g., e-commerce, CRM, or ERP—without the need for deep DBA expertise. Unlike Aurora’s cloud-native design, RDS leverages standard database engines on EC2-like instances with EBS storage, offering familiarity and broad compatibility.
Architecture and Core Components
RDS operates in a VPC, with a regional control plane managing instances deployed in subnets. It uses EC2 instances paired with EBS for storage, replicating via engine-native methods (e.g., MySQL binlog). Key components:
- DB Instance: Compute unit—e.g.,
db.t3.medium(2 vCPUs, 4 GB)—runs the engine. - Storage: EBS volumes—e.g., 100 GB gp3—attached to instances, replicated within AZ.
- Primary/Replica: Primary for writes, read replicas (up to 5) for reads—e.g., Multi-AZ standby.
- Parameter Groups: Engine config—e.g.,
max_connections=200—customizable per instance.
Data durability (99.999%) comes from EBS snapshots; Multi-AZ uses synchronous replication to a standby instance in another AZ—failover in 60-120s.
Engines and Configuration
Engines: MySQL (5.7-8.0), PostgreSQL (11-16), Oracle (19c), SQL Server (2016-2019)—e.g., MySQL 8.0 for compatibility. Instance Types: t3 (burstable), m5 (general), r5 (memory)—e.g., db.m5.large (2 vCPUs, 8 GB). Storage: 20 GB-64 TB, gp3/io1—e.g., 1,000 IOPS base. Multi-AZ: HA—e.g., failover to us-east-1b. Read Replicas: Up to 5, async—e.g., offload reporting. Limits: 40 instances/account—soft limit.
Features and Capabilities
Backups: Automated—e.g., 7-day retention, PITR within 5 mins—snapshots to S3. Multi-AZ: Standby instance—e.g., 99.99% availability. Read Replicas: Scale reads—e.g., promoteable in DR. Encryption: KMS at rest, SSL in transit—e.g., AES-256. Performance Insights: Query analysis—e.g., top SQL by wait time.
Pricing
Instance: $0.017/hr t3.micro, $0.68/hr r5.xlarge—e.g., m5.large $0.34/hr. Storage: $0.115/GB-month gp3, $0.125/GB io1—e.g., 100 GB = $11.50. IOPS: $0.20/1,000 io1—e.g., 3,000 IOPS = $0.60/hr. Multi-AZ/Replicas: Double instance cost—e.g., $0.034/hr t3.micro pair. Free tier: 750 hrs/month t3.micro, 20 GB. Example: t3.medium, 200 GB, Multi-AZ = $62/month ($50 instance + $12 storage).
Networking and Scaling
VPC-based—private subnets, Security Groups (e.g., port 3306). Scaling:
- Vertical: Resize instance—e.g., t3.micro to m5.large, ~5-min downtime.
- Horizontal: Add replicas—e.g., 3 MySQL replicas in us-east-1.
- Storage: Increase—e.g., 100 GB to 200 GB, no downtime.
Example: CRM DB—primary in 1a, standby in 1b, 2 replicas for reads.
Use Cases and Scenarios
E-commerce: MySQL—e.g., orders table, 500 TPS. Enterprise: Oracle—e.g., ERP migration. Reporting: PostgreSQL replicas—e.g., daily analytics. Dev/Test: t3.micro—e.g., quick setup.
Edge Cases and Gotchas
Failover: 60-120s—app must handle reconnects. Replica Lag: Seconds—avoid for real-time. IOPS Bottleneck: gp3 max 16,000—io1 costly ($600/month for 50,000). License Costs: Oracle/SQL Server BYOL—e.g., $1,000s/year extra.
Integration with Other Services
EC2: App connect—e.g., JDBC to MySQL. ALB/NLB: Proxy—e.g., NLB to replicas. CloudWatch: Metrics—e.g., CPUUtilization, alarm on 80%. S3: Backups—e.g., export snapshot. IAM: Auth—e.g., PostgreSQL tokens. Lambda: Queries—e.g., invoke on schedule.
Overview
Amazon Aurora, launched in 2014, is a cloud-native relational database within the RDS family, compatible with MySQL (5x faster) and PostgreSQL (3x faster). Unlike standard RDS’s instance-centric model, Aurora decouples compute from storage, using a distributed, log-structured cluster volume for superior performance, scalability (128 TB), and durability (6 replicas, 11 nines). It’s designed for high-throughput apps—e.g., SaaS, gaming, finance—offering features like Serverless and Global Tables for modern architectures.
Architecture and Core Components
Aurora runs in a VPC, with a regional cluster spanning AZs. Compute (DB instances) is separate from a shared storage layer (SSD-based, 10 GB-128 TB). Key components:
- Cluster: Logical unit—e.g.,
aurora-cluster-1—one writer, up to 15 readers. - DB Instance: Compute—e.g.,
db.t3.medium(2 vCPUs, 4 GB)—writer or reader role. - Cluster Volume: Shared storage—e.g., 100 GB—6 copies across 3 AZs, auto-scaling.
- Endpoint: Access—e.g.,
aurora-cluster-1.cluster-123abc.us-east-1.rds.amazonaws.com—writer/reader endpoints.
Storage uses a log-structured design—writes append to logs, not blocks—replicated 6x (4/6 quorum for writes, 3/6 for reads), self-healing across AZs. Failover in <30s—faster than RDS’s 60-120s.
Engines and Configuration
Engines: Aurora MySQL (5.7-8.0), PostgreSQL (11-15)—e.g., MySQL 8.0 for drop-in replacement. Instance Types: t3, m5, r5—e.g., db.r5.4xlarge (16 vCPUs, 128 GB). Storage: 10 GB-128 TB, auto-scales—e.g., grows 10 GB chunks. Replicas: Up to 15—e.g., 5 readers offload analytics. Serverless: ACUs (2-128)—e.g., auto-pauses. Limits: 40 clusters/account—soft limit.
Features and Capabilities
Serverless: On-demand capacity—e.g., 2-128 ACUs, pauses after inactivity. Global Tables: Multi-region replication—e.g., us-east-1 writer, eu-west-1 reader, <1s lag—each region has its own cluster, storage replicated via log shipping. Backtrack: Rewind—e.g., undo 1 hr in 30s, log-based. Performance: 500,000 reads/sec, 100,000 writes/sec—e.g., log writes bypass block I/O. Encryption: KMS/SSL—e.g., mandatory at rest.
Pricing
Instance: $0.057/hr t3.medium, $0.684/hr r5.xlarge—e.g., $41/month t3.medium. Serverless: $0.06/ACU-hr—e.g., 10 ACUs, 24 hrs = $14.40/day. Storage: $0.10/GB-month—e.g., 100 GB = $10. I/O: $0.20/1M requests—e.g., 1M writes = $0.20. Replicas: Same as primary—e.g., $82/month for 1+1 t3.medium. Example: 1 r5.xlarge, 2 replicas, 200 GB, 10M I/O = $1,670/month ($1,642 instances + $20 storage + $2 I/O).
Networking and Scaling
VPC-based—private subnets, Security Groups (e.g., port 3306). Scaling:
- Vertical: Resize instance—e.g., t3.medium to r5.large, zero-downtime.
- Horizontal: Add replicas—e.g., 5 readers, promoteable in failover.
- Storage: Auto-scales—e.g., 100 GB to 1 TB, no intervention.
- Serverless: ACUs adjust—e.g., 2 to 20 on load.
Example: SaaS app—writer in us-east-1a, 3 readers across AZs, scales to 10 on demand.
Use Cases and Scenarios
High-Throughput: Gaming—e.g., 10,000 TPS on r5.xlarge. Serverless: Dev DB—e.g., auto-pauses overnight. Global Apps: Global Tables—e.g., CRM synced us-east-1 to ap-southeast-1. Recovery: Backtrack—e.g., undo bad update.
Edge Cases and Gotchas
Serverless Cold Start: 5-10s—pre-warm for latency-sensitive apps. I/O Cost: Write-heavy spikes—e.g., 100M I/O = $20/day, optimize queries. Global Lag: <1s—not real-time, plan for eventual consistency. Replica Limits: 15 max—split clusters for more.
Integration with Other Services
EC2: App tier—e.g., JDBC to writer. ALB/NLB: Reader endpoint—e.g., NLB to replicas. CloudWatch: Metrics—e.g., WriteLatency, alarm on 10ms. S3: Backups—e.g., snapshot export. Lambda: Data API—e.g., REST queries. IAM: Auth—e.g., token access.
Overview
Amazon DynamoDB, launched in 2012, is a fully managed NoSQL database service offering single-digit millisecond latency, infinite scalability, and high durability (11 nines). Unlike RDS’s relational model, DynamoDB uses a key-value and document structure—perfect for unstructured data, gaming, IoT, and mobile backends. It’s serverless, auto-scaling, and globally distributed, eliminating provisioning and maintenance—ideal for apps needing fast, flexible data access.
Architecture and Core Components
DynamoDB is a distributed, serverless system across AZs in a region, using a partition-based key-value store (likely built on AWS’s own tech, not open-source). Data replicates synchronously (3 copies/AZ). Key components:
- Tables: Data container—e.g.,
Users—no schema, just partition/sort keys. - Items: Rows—e.g.,
{user_id: "123", name: "Alice"}—up to 400 KB. - Partition Key: Shards data—e.g.,
user_id—distributes across nodes. - Sort Key: Optional—e.g.,
timestamp—orders within partitions. - Indexes: Global (GSI)/Local (LSI)—e.g., GSI on
emailfor queries.
Data is strongly consistent (reads match latest writes) or eventually consistent (faster, ~1s lag)—your choice per request. Partitions auto-split with traffic—e.g., 10 to 20 at 3,000 RCUs.
Capacity and Configuration
Modes: On-Demand—pay-per-request, no planning—vs. Provisioned—set RCUs/WCUs (read/write capacity units). RCUs: 4 KB read/sec—e.g., 1 RCU = 1 strong or 2 eventual reads. WCUs: 1 KB write/sec—e.g., 1 WCU = 1 write. Auto-Scaling: Provisioned—e.g., 100-1,000 RCUs, 70% target. Indexes: 20 GSIs, 5 LSIs/table—soft limits. Size: No limit—e.g., petabytes.
Features and Capabilities
Global Tables: Multi-region—e.g., us-east-1 + eu-west-1, <1s replication. Streams: Change log—e.g., trigger Lambda on INSERT. DAX: In-memory cache—e.g., 1ms to 100µs reads, $0.04/hr/node. TTL: Auto-delete—e.g., expire session after 24 hrs. Transactions: ACID—e.g., update 2 items atomically, 100 ops max.
Pricing
On-Demand: $1.25/1M WCUs, $0.25/1M RCUs—e.g., 1M reads = $0.25. Provisioned: $0.00065/RCU-hr, $0.00013/WCU-hr—e.g., 100 RCUs, 50 WCUs, 24 hrs = $1.73/day. Storage: $0.25/GB-month—e.g., 100 GB = $25/month. Extras: Streams $0.02/100K units, DAX $0.04/hr/node. Free tier: 25 GB, 25 RCUs/WCUs—forever.
Networking and Scaling
Serverless—no VPC by default, optional VPC Endpoint (private access). Scaling:
- Auto-Scaling: Provisioned—e.g., 100-500 RCUs, adjusts in minutes.
- On-Demand: Instant—e.g., 1 to 1M requests/sec, no config.
- Indexes: GSIs scale independently—e.g., 200 RCUs for
emailGSI.
Example: Gaming app—Players table scales from 1,000 to 10,000 RCUs on demand.
Use Cases and Scenarios
Gaming: Leaderboards—e.g., player_id key, 10M reads/day. IoT: Sensor data—e.g., device_id + timestamp, Streams to Lambda. E-commerce: Cart—e.g., user_id, transactions for checkout. Global Apps: Multi-region—e.g., user profiles across 3 regions.
Edge Cases and Gotchas
Hot Keys: Uneven partition load—e.g., user_id=1 floods one shard—randomize keys. 400 KB Limit: Items capped—use S3 for blobs. Throttling: Exceed RCUs/WCUs—e.g., 503 errors, exponential backoff. DAX Cost: $1/day/node—overkill for low traffic. Streams Lag: Seconds—not real-time.
Integration with Other Services
Lambda: Triggers—e.g., Streams process updates. S3: Store large data—e.g., s3://media. CloudWatch: Metrics—e.g., ThrottledRequests, alarm on spikes. IAM: Fine-grained—e.g., PutItem only. DAX: Cache—e.g., 90% read reduction. Global Tables: Multi-region—e.g., sync with ELB.
Overview
Amazon ElastiCache, launched in 2011, is a managed in-memory caching service supporting Redis and Memcached, delivering sub-millisecond latency for read-heavy workloads. Unlike RDS (persistent) or DynamoDB (NoSQL), ElastiCache is ephemeral—data lives in RAM, boosting performance for apps like gaming, real-time analytics, or session stores. It’s fully managed, scalable, and HA-ready, reducing database load by caching frequent queries.
Architecture and Core Components
ElastiCache runs in a VPC, using EC2-like nodes across AZs (Redis) or a flat cluster (Memcached). Data is in-memory, with optional persistence (Redis). Key components:
- Cluster: Group of nodes—e.g.,
my-cache-cluster—Redis (sharded or not), Memcached (flat). - Nodes: Compute—e.g.,
cache.t3.micro(1 vCPU, 0.5 GB)—primary + replicas (Redis). - Shard (Redis): Data partition—e.g., 2 shards, 10 GB each—replicated for HA.
- Endpoint: Access—e.g.,
my-cache-cluster.123abc.clustercfg.use1.cache.amazonaws.com:6379.
Redis replicates synchronously (primary-replica); Memcached doesn’t—data splits across nodes. Durability via Redis AOF/RDB—e.g., snapshots to S3.
Engines and Configuration
Redis: 5.0-7.x—pub/sub, Lua, persistence—e.g., 1-500 shards, up to 500 nodes. Memcached: 1.4-1.6—simple key-value, no replication—e.g., 1-20 nodes. Instance Types: t3, m5, r5—e.g., cache.r5.xlarge (4 vCPUs, 32 GB). Data Size: Up to 635 GB/node (Redis), 128 GB (Memcached). Multi-AZ: Redis—e.g., failover in 30s. Limits: 500 nodes/cluster—soft limit.
Features and Capabilities
Redis: Multi-AZ, read replicas (5/shard)—e.g., 3 replicas offload reads. Persistence: AOF (every write), RDB (snapshots)—e.g., hourly backups. Pub/Sub: Messaging—e.g., SUBSCRIBE updates. Memcached: Auto-discovery—e.g., client finds nodes. Encryption: In-transit/at-rest—e.g., TLS, KMS.
Pricing
Nodes: $0.017/hr t3.micro, $0.684/hr r5.xlarge—e.g., 2 t3.micro, 24 hrs = $0.82/day. Backups: $0.085/GB-month—e.g., 10 GB = $0.85/month. Replicas: Same as primary—e.g., 1+1 r5.xlarge = $1.37/hr. Free tier: 750 hrs/month t3.micro. Example: Redis 1 r5.xlarge, 1 replica, 10 GB backup = $1,650/month.
Networking and Scaling
VPC-based—private subnets, Security Groups (e.g., port 6379). Scaling:
- Vertical: Resize—e.g., t3.micro to m5.large, ~5-min downtime (Memcached), zero-downtime (Redis).
- Horizontal: Add shards/replicas (Redis)—e.g., 2 to 4 shards; nodes (Memcached)—e.g., 5 to 10.
Example: Session store—1 primary, 2 replicas, scales to 4 on load.
Use Cases and Scenarios
Caching: RDS offload—e.g., top 10 products, 1ms reads. Sessions: Web app—e.g., session:user123 in Redis. Real-Time: Leaderboards—e.g., Redis sorted sets, 100µs updates. Pub/Sub: Chat—e.g., Redis channels.
Edge Cases and Gotchas
Data Loss: Memcached ephemeral—restart wipes all; Redis AOF corruption—restore from RDB. Failover: Redis 30s—app must retry. Cost: r5 nodes pricey—e.g., $500/month vs. DAX $30. Shard Imbalance: Redis—uneven keys slow reads—hash evenly.
Integration with Other Services
EC2: App tier—e.g., Redis client. RDS/DynamoDB: Cache—e.g., query results. CloudWatch: Metrics—e.g., CacheHits, alarm on evictions. S3: Backups—e.g., RDB export. Lambda: Cache updates—e.g., invalidate on write. ALB: Route—e.g., to Redis cluster.
Overview
Amazon DocumentDB, launched in 2019, is a fully managed document database compatible with MongoDB (up to 5.0), storing JSON-like documents for flexible, scalable workloads—e.g., user profiles, catalogs. It separates compute and storage, scaling each independently. From basics (inserting a doc) to advanced (sharded clusters, change streams), it handles millions of requests/sec with high availability.
Architecture and Core Components
DocumentDB uses a distributed architecture—compute on EC2, storage on a custom log-structured system—replicating 6x across 3 AZs. Key components:
- Cluster: Instance + storage—e.g.,
my-cluster—primary + up to 15 read replicas. - Document: Data—e.g.,
{"_id": 1, "name": "Alice"}—semi-structured, 16 MB max. - Instance: Compute—e.g.,
db.t3.medium—runs MongoDB-compatible engine. - Storage: Persistent—e.g., 10 GB-64 TB—auto-scales, no pre-provisioning.
Primary writes to storage, replicas read—e.g., 10ms latency—99.9% SLA—failover in ~30s.
Features and Configuration
Basics: Create—e.g., aws docdb create-db-cluster --db-cluster-id my-cluster --engine docdb --master-username admin—Insert—e.g., db.users.insertOne({"name": "Alice"})—Query—e.g., db.users.find(). Intermediate: Replica—e.g., aws docdb create-db-instance --db-instance-id replica1—Indexes—e.g., db.users.createIndex({"name": 1})—Backup—e.g., PITR to 35d. Advanced: Sharding—e.g., manual via mongos—Change Streams—e.g., db.users.watch()—Global Clusters—e.g., aws docdb create-global-cluster—Encryption—e.g., KMS—VPC—e.g., private subnet. Config: TTL—e.g., expire docs—Limits: 64 TB, 15 replicas—soft limits.
Pricing
Instances: db.t3.medium—$0.078/hr ($56.16/month)—db.r5.large—$0.312/hr ($224.64/month). Storage: $0.10/GB-month—e.g., 100 GB = $10/month—I/O—$0.20/1M requests. Free tier: None. Example: db.r5.large, 2 replicas, 100 GB, 10M I/O = $721.92/month ($673.92 + $10 + $38).
Use Cases and Scenarios
Basic: Profiles—e.g., {"user_id": 123}—Content—e.g., articles. Intermediate: Catalog—e.g., product JSON—Mobile—e.g., app data sync. Advanced: Streams—e.g., real-time updates—Global—e.g., multi-region reads.
Edge Cases and Gotchas
Compatibility: MongoDB 5.0—e.g., no 6.0 features—test app—Sharding—e.g., manual, no auto—plan ahead. I/O Cost: 1B requests—e.g., $200/month—cache with ElastiCache. Storage: Auto-grow only—e.g., no shrink—monitor usage. Failover: 30s—e.g., app retry logic needed.
Integration with Other Services
ElastiCache: Cache—e.g., query results—find(). Lambda: Trigger—e.g., change stream—S3: Backup—e.g., export JSON. CloudWatch: Metrics—e.g., DatabaseConnections. IAM: Auth—e.g., docdb:Connect.
Overview
Amazon Neptune, launched in 2017, is a fully managed graph database for highly connected data—e.g., social networks, fraud detection—supporting Property Graph (Gremlin) and RDF (SPARQL). It’s optimized for low-latency traversals, scaling to billions of relationships. From basics (adding nodes) to advanced (ML inference, global DB), Neptune powers complex queries with millisecond performance.
Architecture and Core Components
Neptune uses a purpose-built graph engine on EC2 + custom storage, replicating 6x across 3 AZs. Key components:
- Cluster: Graph—e.g.,
my-graph—primary + up to 15 read replicas. - Node/Edge: Data—e.g., Gremlin
g.addV('user').property('id', 1)—relationships. - Instance: Compute—e.g.,
db.t3.medium—runs graph engine. - Storage: Auto-scales—e.g., 10 GB-64 TB—optimized for traversals.
Primary writes, replicas read—e.g., 5ms query—99.99% SLA with Multi-AZ—failover in ~30s.
Features and Configuration
Basics: Create—e.g., aws neptune create-db-cluster --db-cluster-id my-graph --engine neptune—Add—e.g., Gremlin g.addV('user')—Query—e.g., g.V().has('id', 1). Intermediate: Replica—e.g., aws neptune create-db-instance—SPARQL—e.g., SELECT ?s WHERE { ?s a —Streams—e.g., aws neptune get-stream. Advanced: Neptune ML—e.g., aws neptune create-ml-endpoint—Global DB—e.g., aws neptune create-global-cluster—Encryption—e.g., KMS—VPC—e.g., private access. Config: Bulk Load—e.g., S3 CSV—Limits: 64 TB, 15 replicas—soft limits.
Pricing
Instances: db.t3.medium—$0.087/hr ($62.64/month)—db.r5.large—$0.348/hr ($250.56/month). Storage: $0.10/GB-month—I/O—$0.20/1M requests—ML—$0.368/hr + $0.023/GB inference. Free tier: None. Example: db.r5.large, 2 replicas, 100 GB, 10M I/O = $803.28/month ($751.68 + $10 + $41.60).
Use Cases and Scenarios
Basic: Social—e.g., friends-of-friends. Intermediate: Fraud—e.g., detect cycles—Recommendations—e.g., g.V(1).out('likes'). Advanced: ML—e.g., predict links—Knowledge Graphs—e.g., SPARQL ontologies.
Edge Cases and Gotchas
Query Cost: Deep traversals—e.g., 1M I/O = $200—optimize paths. ML: Training—e.g., hours—pre-aggregate—Cost—e.g., $500/month—limit usage. Storage: No shrink—e.g., 64 TB max—plan growth. Streams: Lag—e.g., 1s—tune polling.
Integration with Other Services
S3: Load—e.g., CSV import—Backup—e.g., snapshots. Lambda: Query—e.g., Gremlin API. CloudWatch: Metrics—e.g., QueryLatency. IAM: Access—e.g., neptune-db:Query.
Overview
Amazon Keyspaces, launched in 2020, is a managed, serverless Apache Cassandra-compatible database for wide-column, key-value workloads—e.g., time-series, messaging. It scales throughput and storage on demand, supporting CQL (Cassandra Query Language). From basics (table creation) to advanced (PITR, multi-region), Keyspaces handles thousands of requests/sec with no servers to manage.
Architecture and Core Components
Keyspaces is a serverless, distributed system—likely DynamoDB-like under the hood—replicating 3x across AZs. Key components:
- Keyspace: Namespace—e.g.,
my_keyspace—groups tables. - Table: Data—e.g.,
users—rows with partition + clustering keys. - Row: Record—e.g.,
user_id=1, timestamp=2025-03-16, value=xyz—64 KB max. - Throughput: Capacity—e.g., On-Demand or Provisioned RCUs/WCUs.
Writes replicate synchronously—e.g., 10ms—reads via quorum—99.99% SLA—serverless scaling.
Features and Configuration
Basics: Create—e.g., aws keyspaces create-keyspace --keyspace-name my_keyspace—Table—e.g., CREATE TABLE my_keyspace.users (user_id text PRIMARY KEY)—Insert—e.g., INSERT INTO users (user_id) VALUES ('1'). Intermediate: Provisioned—e.g., aws keyspaces update-table --capacity-specification throughputMode=PROVISIONED—Query—e.g., SELECT * FROM users WHERE user_id='1'. Advanced: PITR—e.g., aws keyspaces restore-table --target-table-name users_restored—Multi-Region—e.g., aws keyspaces create-multi-region-table—Encryption—e.g., KMS—TTL—e.g., ALTER TABLE users WITH default_time_to_live=86400. Config: Indexes—e.g., CREATE INDEX ON users (timestamp)—Limits: 1M tables—soft limit.
Pricing
On-Demand: $1.45/1M writes—$0.46/1M reads—$0.12/GB-month—e.g., 1M writes, 10M reads, 100 GB = $20.50/month. Provisioned: $0.72/1K WCU-hr—$0.144/1K RCU-hr—e.g., 1K WCU, 5K RCU = $36/day. Free tier: 400 RCUs, 1K WCUs, 1 GB—30 days. Example: On-Demand, 10M writes, 50M reads, 500 GB = $258/month.
Use Cases and Scenarios
Basic: Messaging—e.g., chat_logs. Intermediate: Time-Series—e.g., sensor_data—Fleet—e.g., vehicle status. Advanced: Multi-Region—e.g., global app—PITR—e.g., recover deletes.
Edge Cases and Gotchas
Throughput: Throttle—e.g., exceed 1K WCUs—scale up—Hot Keys—e.g., 90% to user_id=1—redesign schema. PITR: 35d max—e.g., older data lost—export to S3. Cost: 1B reads—e.g., $460/month—cache with ElastiCache.
Integration with Other Services
ElastiCache: Cache—e.g., SELECT results—Lambda: Write—e.g., CQL via SDK. S3: Export—e.g., backups—CloudWatch: Metrics—e.g., ReadThrottleEvents. IAM: Access—e.g., cassandra:Select.
Overview
Amazon QLDB (Quantum Ledger Database), launched in 2019, is a fully managed ledger database for immutable, cryptographically verifiable transaction logs—e.g., financial records, supply chain. It uses PartiQL (SQL-like) for queries and ensures tamper-proof history. From basics (inserting entries) to advanced (streaming changes), QLDB scales to millions of transactions with centralized trust.
Architecture and Core Components
QLDB is serverless—likely a log-structured store—replicating 3x across AZs. Key components:
- Ledger: Database—e.g.,
my-ledger—immutable log + tables. - Journal: History—e.g., every change cryptographically hashed—append-only.
- Table: Data—e.g.,
transactions—JSON-like docs, 32 MB max. - Stream: Export—e.g., changes to Kinesis—real-time.
Writes append to journal—e.g., SHA-256 verified—reads from indexed views—99.99% SLA.
Features and Configuration
Basics: Create—e.g., aws qldb create-ledger --name my-ledger—Insert—e.g., INSERT INTO transactions VALUE {'id': 1, 'amount': 100}—Query—e.g., SELECT * FROM transactions. Intermediate: Index—e.g., CREATE INDEX ON transactions (id)—History—e.g., SELECT * FROM history(transactions)—Stream—e.g., aws qldb create-ledger-stream. Advanced: Verification—e.g., aws qldb verify-document—Encryption—e.g., KMS—Deletion—e.g., aws qldb delete-ledger (after export). Config: Retention—e.g., infinite—Limits: 40K writes/sec—soft limit.
Pricing
Writes: $0.0306/1M requests—Reads—$0.00612/1M—Storage—$0.12/GB-month—Streams—$0.0075/100K units—e.g., 1M writes, 10M reads, 100 GB, 1M stream units = $43.62/month. Free tier: None. Example: 10M writes, 50M reads, 500 GB = $671/month.
Use Cases and Scenarios
Basic: Audit—e.g., payment_logs. Intermediate: Finance—e.g., trades—Supply—e.g., shipments. Advanced: Streams—e.g., real-time fraud—History—e.g., compliance checks.
Edge Cases and Gotchas
Immutable: No deletes—e.g., errors permanent—validate inputs—Writes—e.g., 40K/sec limit—batch ops. Cost: 1B writes—e.g., $306/month—archive old data—Streams—e.g., lag—tune Kinesis.
Integration with Other Services
Kinesis: Stream—e.g., changes—Lambda: Process—e.g., PartiQL SDK. S3: Export—e.g., aws qldb export-ledger-to-s3—CloudWatch: Metrics—e.g., WriteIOs. IAM: Access—e.g., qldb:SendCommand.
Overview
Amazon Timestream, launched in 2020, is a serverless time-series database for IoT, DevOps, and operational data—e.g., sensor readings, logs—optimized for trillion-event/day ingestion and analysis. It tiers data (memory for recent, magnetic for historical) with SQL queries. From basics (inserting events) to advanced (scheduled queries, multi-measure), Timestream scales cost-effectively with time-ordered data.
Architecture and Core Components
Timestream is serverless—ingestion tier + dual storage (memory + magnetic)—replicating 3x across AZs. Key components:
- Table: Series—e.g.,
sensors—time-ordered rows. - Record: Event—e.g.,
{"time": "2025-03-16T12:00:00Z", "temp": 23}—append-only. - Memory Store: Recent—e.g., 1h-1y—fast queries.
- Magnetic Store: Historical—e.g., 1y-200y—cost-optimized.
Writes to memory, auto-tiers to magnetic—e.g., 10ms latency—99.99% SLA—scales infinitely.
Features and Configuration
Basics: Create—e.g., aws timestream-write create-table --database-name my-db --table-name sensors—Insert—e.g., aws timestream-write write-records --records '[{"MeasureName": "temp", "MeasureValue": "23"}]'—Query—e.g., SELECT * FROM sensors. Intermediate: Retention—e.g., memory=24h, magnetic=365d—Window—e.g., SELECT AVG(temp) FROM sensors GROUP BY time_bucket('5m'). Advanced: Scheduled Queries—e.g., aws timestream-query create-scheduled-query—Multi-Measure—e.g., temp,pressure in one record—Encryption—e.g., KMS—VPC—e.g., private endpoint. Config: Tags—e.g., env=prod—Limits: 50K writes/sec—soft limit.
Pricing
Writes: $0.036/1M—Memory—$0.50/GB-month—Magnetic—$0.03/GB-month—Queries—$0.01/GB scanned—e.g., 1M writes, 10 GB memory, 100 GB magnetic, 10 GB query = $8.86/month. Free tier: 100M writes, 2 GB memory, 10 GB magnetic—30 days. Example: 10M writes, 50 GB memory, 1 TB magnetic = $58/month.
Use Cases and Scenarios
Basic: Logs—e.g., app_events. Intermediate: IoT—e.g., temp_sensors—DevOps—e.g., metrics. Advanced: Analytics—e.g., trends—Scheduled—e.g., daily reports.
Edge Cases and Gotchas
Writes: Throttle—e.g., 50K/sec—batch records—Late Data—e.g., 1y delay—rejected unless magnetic. Cost: Queries—e.g., 1 TB scan = $10—optimize filters—Memory—e.g., $500/month for 1 TB—tune retention.
Integration with Other Services
Kinesis: Ingest—e.g., stream to table—Lambda: Process—e.g., query SDK. S3: Export—e.g., scheduled output—CloudWatch: Metrics—e.g., WriteRecords. IAM: Access—e.g., timestream:WriteRecords.
Analytics Services
AWS analytics solutions for querying, data warehousing, visualization, big data processing, and streaming.
Overview
Amazon Athena, launched in 2016, is a serverless, interactive query service that lets you analyze data in S3 using standard SQL—no infrastructure to manage. Built on Presto, it’s perfect for ad-hoc queries, log analysis, or lightweight analytics, scaling automatically from small CSVs to petabytes of parquet data. From basics (querying a single file) to advanced (federated queries across databases), Athena offers fast, cost-effective analytics without provisioning servers.
Architecture and Core Components
Athena is a fully managed, serverless engine running on AWS’s distributed compute fabric—likely Presto clusters under the hood—integrated with S3 and AWS Glue. Key components:
- Data Source: S3 buckets—e.g.,
s3://my-logs/—no data movement, queried in place. - Catalog: Glue Data Catalog—e.g., database
logs_db, tableaccess_logs—defines schema (columns, partitions). - Query Engine: Serverless Presto—e.g.,
SELECT * FROM logs_db.access_logs WHERE status = 200—scales with data size. - Output: S3—e.g.,
s3://athena-results/—CSV, JSON, parquet results.
Data stays in S3—Athena spins up compute on demand, scans only queried data (partitioned for efficiency), and writes results back to S3. No persistence—pure pay-per-query model.
Features and Configuration
Basics: SQL—e.g., SELECT count(*) FROM logs_db.access_logs—run via console, CLI (aws athena start-query-execution), SDK. Schema: Glue tables—e.g., CREATE EXTERNAL TABLE access_logs (ip STRING) LOCATION 's3://my-logs/'—manual or crawler-generated. Formats: CSV, JSON, parquet, ORC, Avro—e.g., parquet for columnar efficiency. Intermediate: Partitions—e.g., s3://my-logs/year=2025/month=03/—PARTITIONED BY (year STRING, month STRING)—cuts scan costs. Advanced: Federated Queries—e.g., join S3 with RDS via Lambda connector (athena-federation-sdk); CTAS—e.g., CREATE TABLE parquet_logs AS SELECT * FROM csv_logs—convert formats; Workgroups—e.g., dev vs. prod, separate billing/limits. Limits: 20,000 partitions/table, 100 databases—soft limits.
Pricing
Queries: $5/TB scanned—e.g., 10 GB = $0.05/query—billed per 10 MB minimum. Glue: $1/crawler run, $0.44/100K objects—e.g., 1M objects = $4.40/month. S3: Storage—$0.023/GB-month—e.g., 100 GB = $2.30; Output—$0.09/GB out. Free tier: None—starts at $0.05/query. Example: 1 TB parquet, partitioned (10 GB scanned) = $0.05/query + $0.01 S3 = $0.06 total.
Analytics and Scaling
Serverless—scales to petabytes:
- Basic: Query CSV—e.g.,
SELECT * FROM sales LIMIT 10—10 MB scanned. - Intermediate: Partitioned logs—e.g.,
SELECT ip FROM access_logs WHERE year = '2025' AND month = '03'—100 GB to 1 GB scanned. - Advanced: Federated—e.g.,
SELECT a.ip, r.user FROM access_logs a JOIN rds.users r ON a.user_id = r.id—cross-source; CTAS—e.g., compress 1 TB CSV to 100 GB parquet—10x savings.
Example: Web logs—s3://logs/ partitioned by date, SELECT count(*) FROM access_logs WHERE status = 404—scales from 1 GB to 1 PB, $0.05 to $5/query.
Use Cases and Scenarios
Basic: Ad-hoc—e.g., SELECT sum(revenue) FROM sales on S3 CSV. Logs: ELB logs—e.g., SELECT ip, count(*) FROM elb_logs GROUP BY ip. Data Lake: Parquet—e.g., SELECT avg(price) FROM products—partitioned by region. Federated: S3 + DynamoDB—e.g., join logs with user data.
Edge Cases and Gotchas
Cost Spikes: Unpartitioned—e.g., 1 TB scan = $5/query—partition or use CTAS. Schema Drift: New columns—e.g., CSV adds new_field—crawler misses, manual ALTER TABLE. Federation Latency: RDS join—e.g., 10s vs. 1s—optimize Lambda connector. Query Limits: 30-min timeout—e.g., 10 TB scan fails—split queries. Glue Cost: 1M objects—e.g., $4.40/month—limit crawler scope.
Integration with Other Services
S3: Data source/output—e.g., s3://my-logs/. Glue: Catalog—e.g., logs_db.access_logs. Lambda: Federation—e.g., RDS connector. QuickSight: Viz—e.g., dashboard from Athena results. CloudWatch: Metrics—e.g., BytesScanned, alarm on $10/day. IAM: Permissions—e.g., {"Action": "athena:StartQueryExecution", "Resource": "*"}.
Overview
Amazon Redshift, launched in 2012, is a fully managed, petabyte-scale data warehouse for structured analytics—think complex SQL joins, aggregations, and reporting. Built on a columnar, massively parallel processing (MPP) architecture, it’s optimized for OLAP (online analytical processing), not OLTP (like RDS). From basics (loading CSVs) to advanced (Spectrum for S3, RA3 nodes), Redshift powers enterprise BI, data lakes, and big data analytics with high performance and concurrency.
Architecture and Core Components
Redshift runs in a VPC, using a cluster-based MPP design—leader node coordinates, compute nodes process (Postgres-based). Key components:
- Cluster: Core unit—e.g.,
my-redshift-cluster—1 leader, 1+ compute nodes. - Leader Node: Query planning—e.g., parses
SELECT sum(sales) FROM orders—SQL endpoint. - Compute Nodes: Data storage/processing—e.g.,
dc2.large(2 vCPUs, 15 GB)—columnar, parallel execution. - Storage: Node-based (DC/DS)—e.g., 160 GB/node—or RA3 (managed, 64 TB/node)—decoupled compute/storage.
- Snapshot: Backups—e.g., to S3, automated daily.
Data distributes via keys—e.g., DISTKEY(customer_id)—shards across nodes; SORTKEY(date) speeds range queries. Spectrum extends to S3—e.g., SELECT * FROM s3://external-table—no data load.
Features and Configuration
Basics: Nodes—e.g., dc2.large (2 vCPUs, 15 GB, 160 GB)—SQL—e.g., COPY orders FROM 's3://my-data/orders.csv'. Intermediate: Distribution—e.g., DISTSTYLE EVEN—Sort—e.g., SORTKEY(order_date)—Concurrency—e.g., 50 queries via WLM (Workload Management). Advanced: Spectrum—e.g., CREATE EXTERNAL TABLE sales_ext (id INT) STORED AS PARQUET LOCATION 's3://my-lake/'—RA3—e.g., ra3.4xlarge (12 vCPUs, 96 GB, 64 TB)—AQUA—e.g., hardware-accelerated aggregates, 10x faster. Config: Multi-AZ—e.g., failover in 60s—Encryption—e.g., KMS. Limits: 200 nodes, 1 PB (non-RA3)—soft limits.
Pricing
Nodes: DC2—$0.25/hr dc2.large, $4.80/hr dc2.8xlarge—RA3—$13.04/hr ra3.16xlarge + $0.024/GB-month—e.g., 2 dc2.large = $12/day. Spectrum: $5/TB scanned—e.g., 100 GB = $0.50/query. Backup: $0.021/GB-month—e.g., 1 TB = $21/month. Free tier: 2 dc2.large hrs/month—750 hrs = $0.50/month. Example: 4 ra3.4xlarge, 1 TB, 10 TB Spectrum = $1,600/month ($1,562 nodes + $24 storage + $14 Spectrum).
Analytics and Scaling
Scales via nodes/storage:
- Basic: 1
dc2.large—e.g.,SELECT count(*) FROM orders—100 GB. - Intermediate: 4 nodes—e.g.,
SELECT c.name, sum(o.total) FROM customers c JOIN orders o—1 TB, 50 users. - Advanced: RA3—e.g., 10 nodes, 640 TB—Spectrum—e.g., join 1 PB S3 parquet—AQUA—e.g.,
SELECT avg(price) FROM sales—10x speedup.
Example: Retail DW—4 ra3.4xlarge, orders (1 TB), Spectrum sales_ext (10 TB)—scales to 100 concurrent queries.
Use Cases and Scenarios
Basic: Reporting—e.g., SELECT sum(revenue) FROM sales. BI: Tableau—e.g., joins on 10M rows. Data Lake: Spectrum—e.g., S3 + Redshift for 1 PB analytics. Enterprise: RA3—e.g., 100 TB DW for finance.
Edge Cases and Gotchas
Concurrency: 50 queries max—e.g., WLM queues overflow—tune queues. Spectrum Cost: Unpartitioned—e.g., 1 TB = $5/query—partition S3. Resize Downtime: Classic—e.g., 10-20 mins—RA3 elastic—e.g., ~5 mins. Data Skew: Bad DISTKEY—e.g., 90% on 1 node—redistribute. AQUA Limits: Aggregates only—e.g., no joins—check compatibility.
Integration with Other Services
S3: Load/Spectrum—e.g., COPY FROM 's3://data/'. Glue: Catalog—e.g., external tables. QuickSight: Viz—e.g., dashboards. Lambda: Triggers—e.g., ETL on S3 upload. CloudWatch: Metrics—e.g., QueryRuntime, alarm on 80% CPU. IAM: Access—e.g., redshift:DescribeClusters.
Overview
Amazon QuickSight, launched in 2015, is a fully managed business intelligence (BI) service that transforms data from AWS services (e.g., Athena, Redshift, S3) or external sources (e.g., MySQL, Salesforce) into interactive dashboards and visualizations. It’s serverless, scalable, and user-friendly—drag-and-drop for beginners, custom SQL for pros. From basic charts to advanced ML-driven insights and embedded analytics, QuickSight powers data-driven decisions for teams or enterprises, handling millions of data points with ease.
Architecture and Core Components
QuickSight is a serverless BI platform, with AWS managing the compute and rendering layers, tightly integrated with SPICE (Super-fast, Parallel, In-memory Calculation Engine). Key components:
- Data Source: Connection—e.g., Redshift
my-cluster, S3my-bucket—via JDBC/ODBC or AWS APIs. - SPICE: In-memory store—e.g., 10 GB dataset—low-latency queries, auto-refreshed from sources.
- Dataset: Logical view—e.g.,
sales_datafrom Athena—supports joins, filters, calculated fields. - Analysis: Viz workspace—e.g., bar chart of
sales by region—interactive, built in-browser. - Dashboard: Published output—e.g.,
sales-dashboard—shared with users or embedded.
Data flows two ways: SPICE (cached, fast) or live queries (direct to source, slower)—e.g., Athena SQL hits S3, rendered as a line graph. No user-managed servers—scales automatically.
Features and Configuration
Basics: Visuals—e.g., pie chart from SELECT category, sum(sales) FROM sales_data—CSV upload—e.g., aws quicksight create-data-set --data-source-id ... --physical-table-map ...—Console drag-and-drop—e.g., revenue to Y-axis. Intermediate: SPICE—e.g., import 100 GB from Redshift—Filters—e.g., year = 2025—Joins—e.g., sales + customers on customer_id—Schedules—e.g., refresh daily at 2 AM. Advanced: ML Insights—e.g., forecast sales next quarter—Embedded—e.g., <iframe src='https://quicksight.aws.amazon.com/embed/...'>—Custom SQL—e.g., SELECT * FROM athena.sales WHERE price > 100—Q—e.g., “what are my top 5 products?”—VPC—e.g., private RDS access via aws quicksight create-vpc-connection. Config: Encryption—e.g., KMS—Permissions—e.g., user alice views only. Limits: 1 TB SPICE/user, 1M rows/upload—soft limits.
Pricing
Standard Edition: $12/user/month—10 GB SPICE—e.g., 5 authors = $60/month. Enterprise Edition: $24/user/month—50 GB SPICE, SSO, AD—e.g., 10 authors = $240/month. SPICE: $0.38/GB-month—e.g., 100 GB = $38/month—first 10 GB free/author. Readers: $0.30/session (max $5/user/month)—e.g., 100 sessions = $30/month. Free tier: 1 author, 1 GB SPICE—forever. Example: Enterprise, 5 authors, 200 GB SPICE, 50 readers (100 sessions) = $226/month ($120 + $76 + $30).
Analytics and Scaling
Scales with users and data volume:
- Basic: Bar chart—e.g.,
sales by categoryfrom 1 GB S3 CSV—1 user, 1 GB SPICE. - Intermediate: Dashboard—e.g., 10 visuals from Redshift (sales, inventory)—10 users, 50 GB SPICE—daily refresh.
- Advanced: ML—e.g., anomaly detection on 1 TB Athena data—Embedded—e.g., 1,000 readers in CRM—Q—e.g., “show revenue trends”—1 TB SPICE, 100 users.
Example: Retail analytics—5 authors build sales-dashboard (100 GB SPICE from Redshift), 50 readers view—scales to 100 dashboards, 10M rows processed.
Use Cases and Scenarios
Basic: Quick report—e.g., bar chart from uploaded CSV. Team Analytics: Dashboard—e.g., Redshift sales viz for 10 users—scheduled refresh. Enterprise BI: Embedded—e.g., live analytics in a SaaS app—ML—e.g., detect order spikes. Self-Service: Q—e.g., “top customers this year” for non-tech users.
Edge Cases and Gotchas
SPICE Refresh: Manual lag—e.g., 1h stale data—schedule auto-refresh (min 15m)—failures—e.g., source down—retry manually. Cost Creep: 1 TB SPICE—e.g., $380/month—use live queries for transient data—Readers—e.g., 100 users, 10 sessions/day = $150/month—cap at $5/user. ML Limits: Numeric only—e.g., no text forecasts—pre-process in Athena—5M rows max—e.g., large datasets fail—aggregate first. VPC Latency: Private RDS—e.g., 2s vs. 0.5s live—cache in SPICE. Data Prep: Joins—e.g., mismatched keys—null results—validate in dataset.
Integration with Other Services
Athena: Queries—e.g., SELECT * FROM sales_data—live or SPICE. Redshift: DW—e.g., orders table—large-scale source. S3: Upload—e.g., s3://data/sales.csv—raw data import. RDS: Live—e.g., MySQL via VPC—real-time viz. CloudWatch: Metrics—e.g., SessionCount, alarm on 100 sessions/day. IAM: Access—e.g., {"Action": "quicksight:CreateDashboard", "Resource": "*"}—SSO—e.g., SAML with AD.
Overview
Amazon EMR (Elastic MapReduce), launched in 2009, is a managed big data platform for processing vast datasets using open-source frameworks like Apache Spark, Hive, and Presto—e.g., log analysis, ETL, ML. It provisions clusters on EC2, EKS, or serverless, scaling to petabytes of data. From basics (running a Spark job) to advanced (Iceberg tables, Lake Formation integration), EMR accelerates analytics at scale with customizable compute and storage.
Architecture and Core Components
EMR orchestrates EC2-based clusters (or serverless)—master, core, task nodes—with frameworks atop Hadoop YARN or Spark Standalone. Key components:
- Cluster: Compute—e.g.,
my-cluster—master (scheduling), core (data + compute), task (compute only). - HDFS: Storage—e.g., local disks—or EMRFS (S3-backed).
- Framework: Engine—e.g., Spark (
spark-submit), Hive (hive -e "SELECT *"), Presto (presto-cli). - Step: Job—e.g.,
aws emr add-steps—runs a script or query.
Data flows from S3/HDFS → cluster → processed output—e.g., Spark reads s3://my-bucket/, writes to s3://output/—99.9% SLA with Multi-AZ.
Features and Configuration
Basics: Create—e.g., aws emr create-cluster --release-label emr-6.15.0 --instance-type m5.xlarge --instance-count 3—Run—e.g., spark-submit --class MyApp s3://my-jar.jar—SSH—e.g., aws emr ssh --cluster-id j-123. Intermediate: Hive—e.g., CREATE TABLE sales—Presto—e.g., SELECT * FROM s3_table—Auto Scaling—e.g., --scale-down-behavior TERMINATE_AT_TASK_COMPLETION—Bootstrap—e.g., --bootstrap-actions Path=s3://my-script.sh. Advanced: Serverless—e.g., aws emr-serverless create-application --release-label emr-6.15.0—Iceberg—e.g., CREATE TABLE iceberg_table with Lake Formation—EKS—e.g., aws emr-containers start-job-run—Spot—e.g., --instance-fleets InstanceFleetType=TASK,TargetSpotCapacity=10—Security—e.g., Kerberos, Lake Formation roles—Encryption—e.g., KMS+S3. Config: Tuning—e.g., spark.executor.memory=4g—Limits: 1,000 steps, soft limits on nodes.
Pricing
EC2: m5.xlarge—$0.192/hr + EMR $0.070/hr = $0.262/hr ($188.64/month)—Serverless—$0.0526/CPU-hr, $0.00526/GB-hr—e.g., 10 CPU-hr, 100 GB = $1.05/job. Storage: S3—$0.023/GB-month—EBS—$0.10/GB-month—e.g., 100 GB = $10/month. Free tier: None. Example: 3x m5.xlarge (24h), 100 GB S3 = $577.92/month ($565.92 + $12).
Analytics and Scaling
Scales to petabytes:
- Basic: Spark—e.g., 1 TB ETL, 3 nodes—10 GB/hour.
- Intermediate: Hive—e.g., 10 TB analytics, 10 nodes—Presto—e.g., ad hoc queries—100 GB/hour.
- Advanced: Serverless—e.g., 1 PB, auto-scales—Iceberg—e.g., ACID on S3—EKS—e.g., Kubernetes jobs—1 TB/hour.
Example: Log pipeline—log-cluster (10 nodes, Spark), S3 input/output—scales to 10M events/sec.
Use Cases and Scenarios
Basic: ETL—e.g., CSV to Parquet—Logs—e.g., app metrics. Intermediate: ML—e.g., Spark MLlib—BI—e.g., Presto + QuickSight. Advanced: Iceberg—e.g., transactional lake—Serverless—e.g., burst workloads.
Edge Cases and Gotchas
Termination: Auto—e.g., idle 1h—costs—e.g., forgot --auto-terminate. Spot: Interrupt—e.g., task loss—use core for data. Serverless: Cold start—e.g., 30s—pre-warm—Limits—e.g., 1,000 vCPUs—request increase. Iceberg: Metadata—e.g., slow on small files—compact regularly.
Integration with Other Services
S3: Input/Output—e.g., s3://data/. Glue: Catalog—e.g., Hive metastore—Lake Formation—e.g., fine-grained access. Lambda: Trigger—e.g., step invoke—Kinesis: Stream—e.g., Spark consumer. CloudWatch: Metrics—e.g., ClusterStatus—Logs—e.g., /aws/emr/.
Overview
AWS Lake Formation, launched in 2018, is a managed service for building, securing, and governing data lakes on S3—e.g., centralizing analytics data. It integrates with Glue for ETL and cataloging, simplifying data ingestion and access control. From basics (registering S3 data) to advanced (row-level security, Iceberg tables), Lake Formation enables analytics and ML at scale with fine-grained permissions.
Architecture and Core Components
Lake Formation leverages S3 (storage), Glue (catalog/ETL), and IAM (identity)—a serverless control layer. Key components:
- Data Lake: S3—e.g.,
s3://my-lake/—raw/transformed zones. - Catalog: Glue—e.g.,
my_db.my_table—metadata for tables. - Permissions: LF Policies—e.g., column-level access—enforced via temp credentials.
- Workflow: Blueprints—e.g., ingest RDS to S3—ETL jobs.
Data flows: S3 → catalog → analytics (e.g., Athena)—permissions vend creds—99.9% SLA—11 9’s durability via S3.
Features and Configuration
Basics: Register—e.g., aws lakeformation register-data-lake-location --location s3://my-lake/—Catalog—e.g., Glue crawler—Grant—e.g., aws lakeformation grant-permissions --principal user:alice --permissions SELECT. Intermediate: Blueprints—e.g., RDS ingest—ETL—e.g., Glue job s3://raw/ → s3://clean/—Tag-Based—e.g., env=prod access—Hybrid Mode—e.g., LF + IAM. Advanced: Row-Level—e.g., WHERE user_id = 123—Iceberg—e.g., ACID tables—Governed Tables—e.g., aws lakeformation create-table-transaction—Federation—e.g., Redshift external tables—Encryption—e.g., KMS—Audit—e.g., CloudTrail logs. Config: Crawlers—e.g., daily—Limits: 1,000 perms—soft limit.
Pricing
Lake Formation: Free—costs from underlying services—Glue Crawlers—$0.44/100K objects—ETL—$0.44/DPU-hr—S3—$0.023/GB-month—e.g., 100 GB, 1 DPU-hr = $2.74/month. Free tier: None—Glue free tier applies. Example: 1 TB S3, 10 DPU-hr ETL, 1M objects crawled = $67.40/month ($23 + $4.40 + $40).
Analytics and Scaling
Scales with S3/Glue:
- Basic: S3—e.g., 1 GB CSV cataloged—Athena—e.g.,
SELECT *—1 GB/hour. - Intermediate: ETL—e.g., 100 GB Parquet—Governed—e.g., 10 users—10 GB/hour.
- Advanced: Iceberg—e.g., 1 TB ACID—Row-Level—e.g., 1,000 users—Federation—e.g., Redshift—1 TB/hour.
Example: Data lake—s3://lake/ (1 PB), Glue ETL, Iceberg queries—scales to 10M rows/sec.
Use Cases and Scenarios
Basic: Catalog—e.g., S3 files—Access—e.g., Athena users. Intermediate: ETL—e.g., clean CSVs—Governance—e.g., PII masking. Advanced: Iceberg—e.g., transactional lake—Federation—e.g., multi-source queries.
Edge Cases and Gotchas
Permissions: Overlap—e.g., IAM + LF—test hierarchy—Row-Level—e.g., slow on 1B rows—index wisely. Iceberg: Compaction—e.g., small files lag—schedule jobs—Cost—e.g., Glue for 1 PB = $4,400/month—optimize DPU. Federation: Latency—e.g., external DB—cache locally.
Integration with Other Services
S3: Storage—e.g., s3://lake/. Glue: Catalog—e.g., metastore—ETL—e.g., jobs—EMR: Access—e.g., Spark SQL—Lake Formation perms. Athena: Query—e.g., SELECT *—Redshift: External—e.g., Spectrum—QuickSight: Viz—e.g., dashboards.
Overview
Amazon MSK, launched in 2018, is a fully managed Apache Kafka service for real-time streaming analytics—e.g., event logs, IoT data—supporting Kafka APIs for producers/consumers. It eliminates Kafka ops overhead, scaling to gigabytes/sec. From basics (creating a cluster) to advanced (Serverless, Connect), MSK powers data lakes, ML, and analytics with high throughput and durability.
Architecture and Core Components
MSK runs Kafka brokers + ZooKeeper on managed EC2—replicating 3x across AZs—or serverless. Key components:
- Cluster: Brokers—e.g.,
my-msk—kafka.m5.large, 1-100 nodes. - Topic: Stream—e.g.,
events—partitioned, replicated (e.g., RF=3). - Partition: Shard—e.g., 1 MB/s in, 2 MB/s out—scales throughput.
- ZooKeeper: Coordination—e.g., managed quorum—ensures consistency.
Producers write to topics—e.g., kafka-console-producer—consumers read—e.g., Lambda polls—99.9% SLA—11 9’s durability via replication.
Features and Configuration
Basics: Create—e.g., aws kafka create-cluster --cluster-name my-msk --broker-node-group-info InstanceType=kafka.m5.large,NumberOfBrokerNodes=3 --kafka-version 3.5.1—Produce—e.g., kafka-console-producer --topic events—Consume—e.g., kafka-console-consumer. Intermediate: Partitions—e.g., --partitions 10—Retention—e.g., aws kafka update-cluster-configuration --log-retention-ms 604800000 (7d)—Monitoring—e.g., CloudWatch BytesInPerSec. Advanced: Serverless—e.g., aws kafka create-serverless-cluster --cluster-name my-serverless—Connect—e.g., aws kafka create-connector—MSK Replicator—e.g., cross-region sync—Encryption—e.g., KMS+TLS—VPC—e.g., private subnets—IAM Auth—e.g., aws kafka update-security. Config: Tuning—e.g., num.replica.fetchers=4—Limits: 1,000 partitions/topic—soft limit.
Pricing
Brokers: kafka.m5.large—$0.21/hr ($151.20/month)—Serverless—$0.0015/partition-hr, $0.40/GB in—e.g., 10 partitions, 1 TB = $11.52/month. Storage: $0.10/GB-month—e.g., 100 GB = $10/month—Transfer—$0.01/GB AZ replication. Free tier: None. Example: 3x kafka.m5.large, 500 GB, 1 TB transfer = $493.60/month ($453.60 + $30 + $10).
Analytics and Scaling
Scales via partitions/brokers:
- Basic: 1 broker—e.g., 1 MB/s logs—Lambda consumer—1 GB/hour.
- Intermediate: 10 brokers—e.g., 100 MB/s IoT—Connect—e.g., S3 sink—10 GB/hour.
- Advanced: Serverless—e.g., 1 GB/s auto-scales—Replicator—e.g., multi-region—1 TB/hour.
Example: Event pipeline—events-msk (10 brokers), Spark consumer—scales to 10M events/sec.
Use Cases and Scenarios
Basic: Logs—e.g., app events—Metrics—e.g., real-time dashboards. Intermediate: Data Lake—e.g., S3 via Connect—CDC—e.g., DB streams. Advanced: ML—e.g., feature streaming—Serverless—e.g., bursty traffic.
Edge Cases and Gotchas
Partitions: Throttle—e.g., 1 MB/s/partition—split topics—Lag—e.g., 1h backlog—increase brokers. Serverless: Cold start—e.g., 10s—pre-warm—Limits—e.g., 10K partitions—request increase. Cost: 100 brokers—e.g., $15K/month—optimize sizing—Transfer—e.g., 1 PB = $10K—minimize AZ hops.
Integration with Other Services
S3: Sink—e.g., Connect—Glue: ETL—e.g., stream to table—EMR: Consumer—e.g., Spark Streaming. Lambda: Process—e.g., topic trigger—Flink: Analytics—e.g., real-time—CloudWatch: Metrics—e.g., OffsetLag.
Application Services
AWS services for building and managing APIs, messaging, notifications, email, streaming, and message brokering.
Overview
Amazon API Gateway, launched in 2015, is a fully managed service for creating, publishing, and securing RESTful and WebSocket APIs at scale. It’s the front door for serverless apps—e.g., Lambda backends—handling requests, throttling, and authentication without servers. Think of it as a proxy that routes HTTP to AWS services or on-prem endpoints, scaling to millions of calls.
Architecture
API Gateway sits in AWS’s edge network—clients hit endpoints (e.g., https://abc123.execute-api.us-east-1.amazonaws.com), routed to integrations (Lambda, HTTP, VPC). Stages (dev, prod) manage versions; resources (/users) and methods (GET, POST) define paths. Mapping templates (Velocity) transform data—e.g., JSON to XML.
Pricing
$3.50/1M REST calls, $1/1M WebSocket messages. Free tier: 1M calls/month.
Use Cases
Serverless APIs: Lambda + API Gateway for CRUD—e.g., POST /users creates in DynamoDB.
Overview
Amazon SQS, launched in 2006, is a fully managed message queueing service for decoupling application components—producers send messages, consumers process asynchronously. It ensures reliable, scalable message delivery (e.g., orders, tasks) with two queue types: Standard (at-least-once) and FIFO (exactly-once). From basics (queuing a task) to advanced (dead-letter queues, long polling), SQS is the backbone of distributed systems, handling millions of messages/sec.
Architecture and Core Components
SQS is a distributed, serverless system—likely a sharded key-value store—replicating messages across AZs in a region. Key components:
- Queue: Message store—e.g.,
my-queue—Standard or FIFO, URL likehttps://sqs.us-east-1.amazonaws.com/123456789012/my-queue. - Message: Payload—e.g.,
{"order_id": "123", "item": "book"}—256 KB max. - Producer: Sender—e.g., Lambda pushes via
aws sqs send-message. - Consumer: Receiver—e.g., EC2 polls via
aws sqs receive-message—deletes after processing. - Dead-Letter Queue (DLQ): Failed messages—e.g.,
my-dlq—after retries.
Messages replicate 3x—Standard allows duplicates, FIFO ensures order. Visibility timeout—e.g., 30s—hides messages during processing. 99.9% delivery SLA.
Features and Configuration
Basics: Standard queue—e.g., aws sqs create-queue --queue-name my-queue—Send—e.g., aws sqs send-message --queue-url ... --message-body "Hello"—Receive—e.g., aws sqs receive-message --queue-url .... Intermediate: FIFO—e.g., my-queue.fifo, MessageGroupId for ordering—Visibility—e.g., 60s timeout—DLQ—e.g., redrive-policy: {"deadLetterTargetArn": "...", "maxReceiveCount": 5}. Advanced: Long polling—e.g., --wait-time-seconds 20—Delay—e.g., 10s/message—Attributes—e.g., MessageDeduplicationId for FIFO—Encryption—e.g., KMS key. Config: Retention—1m-14d (default 4d)—Batch—e.g., 10 messages/send. Limits: 120,000 in-flight messages (Standard), 20,000 (FIFO)—soft limits.
Pricing
Requests: $0.40/1M—e.g., 1M send/receive/delete = $0.40—free tier 1M/month. Data: $0.09/GB out—e.g., 1 GB = $0.09. FIFO: $0.50/1M—e.g., 1M = $0.50. Example: Standard, 10M messages (256 KB each), 2.5 GB out = $4.23 ($4 + $0.23). Free tier: 1M requests—forever.
Decoupling and Scaling
Scales infinitely—millions of messages:
- Basic: Queue—e.g., Lambda → SQS → EC2, 1K messages/day.
- Intermediate: FIFO—e.g., order processing,
MessageGroupId=order123—DLQ—e.g., 5 retries—10K messages/hour. - Advanced: Long polling—e.g., 20s wait, 90% cost cut—Batch—e.g., 10 messages/call—1M messages/sec.
Example: E-commerce—orders-queue.fifo (FIFO, Lambda producer), inventory-queue (Standard, EC2 consumer)—scales to Black Friday peaks.
Use Cases and Scenarios
Basic: Task queue—e.g., image resize jobs. Order Processing: FIFO—e.g., order123 in sequence. Buffering: Standard—e.g., API spikes to slow backend. Retries: DLQ—e.g., failed payments logged.
Edge Cases and Gotchas
Duplicates: Standard—e.g., 2x order123—app dedupe needed. Visibility: Short timeout—e.g., 5s—reappears if slow—extend to 12h max. FIFO Limits: 300 TPS—e.g., split queues for >300—MessageGroupId skew—e.g., 90% to one group—balance groups. Cost: 1B messages—e.g., $400/month—batch to cut requests. DLQ Flood: No retry limit—e.g., infinite loop—set cap.
Integration with Other Services
Lambda: Trigger—e.g., process SQS messages. EC2: Consumer—e.g., poll queue. SNS: Fan-out—e.g., SNS → multiple SQS. S3: Events—e.g., upload → SQS. CloudWatch: Metrics—e.g., NumberOfMessagesSent, alarm on 10K/hour. IAM: Access—e.g., {"Action": "sqs:SendMessage"}.
Overview
Amazon SNS, launched in 2010, is a managed pub/sub messaging service for broadcasting messages to multiple subscribers (e.g., email, SMS, Lambda) in real time. It decouples publishers from subscribers—send once, deliver everywhere. From basics (email alerts) to advanced (fan-out to 100 queues), SNS scales to millions of messages/sec, perfect for notifications, workflows, or event-driven apps.
Architecture and Core Components
SNS is a distributed, serverless system—likely a topic-based message broker—replicating across AZs. Key components:
- Topic: Channel—e.g.,
arn:aws:sns:us-east-1:123456789012:my-topic—pub/sub hub. - Publisher: Sender—e.g., EC2 via
aws sns publish—pushes to topic. - Subscriber: Receiver—e.g., Lambda, SQS, email—subscribed via
aws sns subscribe. - Message: Payload—e.g.,
{"event": "order_placed", "id": "123"}—100 KB max.
Messages fan out—e.g., 1 publish → 10 subscribers—replicated 3x, at-least-once delivery—99.9% SLA.
Features and Configuration
Basics: Topic—e.g., aws sns create-topic --name my-topic—Publish—e.g., aws sns publish --topic-arn ... --message "Order 123"—Subscribe—e.g., aws sns subscribe --topic-arn ... --protocol email --notification-endpoint user@example.com. Intermediate: Protocols—e.g., SMS, HTTP, SQS—Filter—e.g., {"event": ["order_placed"]}—DLQ—e.g., SQS for failed deliveries. Advanced: Fan-out—e.g., 1 topic → 100 SQS—Encryption—e.g., KMS—Message Attributes—e.g., priority=high—FIFO—e.g., my-topic.fifo, ordered delivery. Config: Retry—e.g., 3 attempts—Raw delivery—e.g., no JSON wrapper. Limits: 100,000 topics, 10M subscriptions—soft limits.
Pricing
Requests: $0.50/1M—e.g., 1M publishes = $0.50. Deliveries: Email/SQS—$0.50/1M—SMS—$0.045/message—HTTP—$0.60/1M—e.g., 1M SMS = $45. FIFO: $0.70/1M. Free tier: 1M publishes, 100K HTTP, 1K email/SMS—forever. Example: 1M publishes, 5M SQS deliveries = $3 ($0.50 + $2.50).
Decoupling and Scaling
Scales to millions of subscribers:
- Basic: Alert—e.g., EC2 → SNS → email, 100 messages/day.
- Intermediate: Fan-out—e.g., SNS → 5 SQS—Filter—e.g.,
order_placedonly—1K messages/hour. - Advanced: FIFO—e.g., ordered alerts—100 SQS—e.g., 1M messages/sec—HTTP retries.
Example: Order system—orders-topic (Lambda publish), 10 SQS subscribers—scales to 10M events/day.
Use Cases and Scenarios
Basic: Alerts—e.g., CPU > 80% → email. Workflow: Fan-out—e.g., order → SQS + Lambda. Mobile: SMS—e.g., “Order shipped”. Ordered: FIFO—e.g., sequential updates.
Edge Cases and Gotchas
Duplicates: At-least-once—e.g., 2x “Order 123”—dedupe downstream. SMS Cost: 1M messages—e.g., $45—use sparingly. Filter Miss: Bad policy—e.g., {"event": "wrong"}—no delivery—test filters. FIFO Limits: 300 TPS—e.g., split topics—MessageGroupId skew—e.g., 90% one group—balance. DLQ: No auto-retry—e.g., manual reprocess—set SQS policy.
Integration with Other Services
SQS: Subscriber—e.g., fan-out to queues. Lambda: Trigger—e.g., process SNS. SES: Email—e.g., bulk via SNS. CloudWatch: Metrics—e.g., NumberOfMessagesPublished. IAM: Access—e.g., {"Action": "sns:Publish"}. HTTP: Webhooks—e.g., POST to app.
Overview
Amazon SES, launched in 2011, is a managed email service for sending transactional, marketing, or bulk emails at scale—e.g., order confirmations, newsletters. It’s cost-effective (pennies per 1,000 emails) and integrates with SMTP or AWS SDKs. From basics (sending via console) to advanced (reputation management, dedicated IPs), SES decouples email delivery from your app, scaling to millions of emails/day.
Architecture and Core Components
SES is a regional, serverless email platform—SMTP servers + API—integrated with AWS’s email infrastructure. Key components:
- Identity: Sender—e.g.,
no-reply@example.com—domain or email, verified. - Email: Message—e.g.,
Subject: Order 123, HTML/text—64 KB max. - SMTP/API: Interface—e.g.,
smtp-ses.us-east-1.amazonaws.comoraws ses send-email. - Reputation: Metrics—e.g., bounce/spam rates—tracked per identity.
Emails route via AWS’s mail servers—e.g., SES → recipient ISP—DKIM/SPF signed for deliverability. Sandbox mode—e.g., verified recipients only—until production access.
Features and Configuration
Basics: Verify—e.g., aws ses verify-email-identity --email-address user@example.com—Send—e.g., aws ses send-email --from user@example.com --to client@example.com --subject "Hi" --text "Hello"—SMTP—e.g., port 587, IAM creds. Intermediate: Domain—e.g., example.com with DKIM—Templates—e.g., aws ses create-template --template-name order—Bounce tracking—e.g., SNS notifications. Advanced: Dedicated IPs—e.g., $24.95/month—Configuration Sets—e.g., tag emails for metrics—VPC—e.g., private SMTP—Encryption—e.g., TLS. Config: Limits—e.g., 10 emails/sec—Sandbox—e.g., request production. Limits: 50 identities, 10K recipients/email—soft limits.
Pricing
Emails: $0.10/1,000—e.g., 1M = $0.10—$0.12/1,000 attachments (1 GB free). Receiving: $0.10/1,000—1st 1,000 free/month. Dedicated IPs: $24.95/month/IP. Free tier: 62,000 sent, 1,000 received/month—from EC2. Example: 1M emails, 10 GB attachments, 1 IP = $149.45 ($100 + $24.95 + $24.50).
Decoupling and Scaling
Scales to billions of emails:
- Basic: Transactional—e.g., Lambda → SES, 1K emails/day.
- Intermediate: Bulk—e.g., 100K newsletters via template—SNS bounce—e.g., track failures—10K/hour.
- Advanced: Dedicated IPs—e.g., 1M/day—Config Sets—e.g., A/B test metrics—10M/day.
Example: E-commerce—orders@example.com (transactional), news@example.com (bulk)—scales to holiday surges.
Use Cases and Scenarios
Basic: Alerts—e.g., “Password reset”. Transactional: Orders—e.g., “Shipped 123”. Marketing: Bulk—e.g., 1M promos. Analytics: Bounce—e.g., SNS → Lambda.
Edge Cases and Gotchas
Sandbox: Limited—e.g., verified only—request production delay (24h). Reputation: High bounce—e.g., >5%—throttles sending—clean lists. Cost: 10M emails—e.g., $1,000—optimize campaigns. DKIM: Misconfig—e.g., wrong TXT—spam folder—test SPF/DMARC. Limits: 10 emails/sec—e.g., 1M burst fails—throttle app.
Integration with Other Services
Lambda: Sender—e.g., SES trigger. SNS: Bounce—e.g., notify failures. S3: Logs—e.g., Config Set data. CloudWatch: Metrics—e.g., SentLast24Hours. IAM: Access—e.g., {"Action": "ses:SendEmail"}. Route 53: DKIM—e.g., TXT records.
Overview
Amazon Kinesis, launched in 2013, is a managed platform for real-time data streaming, enabling ingestion, processing, and analysis of high-velocity data—e.g., logs, IoT, clickstreams, video. It comprises four services: Data Streams (raw streaming), Data Firehose (delivery to sinks), Data Analytics (SQL queries), and Video Streams (media). From basics (ingesting logs) to advanced (multi-consumer sharding, Firehose Lambda transforms), Kinesis decouples producers from consumers, scaling to gigabytes/sec with low latency.
Architecture and Core Components
Kinesis is a regional, distributed streaming system—built on sharded queues with serverless compute overlays. Key focus areas:
- Data Streams: Core—e.g.,
my-stream—sharded pipeline, 1 MB/s write, 2 MB/s read per shard—24h-365d retention. - Data Firehose: Delivery—e.g.,
my-firehose—buffers streams to S3, Redshift, etc., with optional transforms. - Data Analytics: SQL—e.g.,
SELECT * FROM my-stream—real-time queries on streams. - Video Streams: Media—e.g.,
my-video-stream—ingests MPEG/H.264 for processing. - Shard: Unit—e.g.,
shardId-0001—partitions data via key (e.g.,user_id). - Record: Payload—e.g.,
{"ts": "2025-03-16T12:00:00Z", "data": "click"}—1 MB max.
Data replicates 3x across AZs—e.g., us-east-1a/b/c—producers write via SDK/CLI, consumers read via Lambda/KCL. Firehose buffers (e.g., 60s), Analytics overlays SQL, Video uses WebRTC—99.9% SLA.
Features and Configuration
Data Streams - Basics: Create—e.g., aws kinesis create-stream --stream-name my-stream --shard-count 1—Put—e.g., aws kinesis put-record --stream-name my-stream --data "Hello" --partition-key user1—Get—e.g., aws kinesis get-shard-iterator --stream-name my-stream --shard-id shardId-0001 --shard-iterator-type TRIM_HORIZON. Intermediate: Shards—e.g., 10 shards = 10 MB/s in, 20 MB/s out—Retention—e.g., aws kinesis increase-stream-retention-period --stream-name my-stream --retention-period-hours 168 (7d)—Consumer—e.g., Lambda polls 1 shard. Advanced: Enhanced Fan-Out—e.g., aws kinesis register-stream-consumer --stream-arn ... --consumer-name my-app—20 MB/s/consumer—KCL—e.g., multi-shard reads with DynamoDB checkpointing—Capacity Modes—e.g., On-Demand (auto-scales to 4 MB/s/shard) vs. Provisioned (manual)—Encryption—e.g., aws kinesis enable-enhanced-monitoring --stream-name my-stream --shard-level-metrics All.
Data Firehose - Basics: Create—e.g., aws firehose create-delivery-stream --delivery-stream-name my-firehose --s3-destination-configuration ...—Put—e.g., aws firehose put-record --delivery-stream-name my-firehose --record '{"data": "log"}'—S3 sink—e.g., s3://my-bucket/. Intermediate: Buffering—e.g., 128 MB or 300s—Compression—e.g., GZIP—Destinations—e.g., Redshift COPY. Advanced: Lambda Transform—e.g., aws firehose update-destination --delivery-stream-name my-firehose --lambda-function-configuration ...—base64 encode, enrich records—Error Handling—e.g., S3 prefix errors/—Encryption—e.g., KMS—Direct PUT vs. Kinesis Stream source.
Data Analytics: SQL—e.g., CREATE PUMP AS INSERT INTO output SELECT STREAM * FROM my-stream WHERE value > 100—Windowing—e.g., WINDOW TUMBLING (INTERVAL 1 MINUTE). Video Streams: RTMP—e.g., aws kinesisvideo put-media --stream-name my-video-stream—HLS playback—e.g., 10s chunks—5 Gbps/shard.
Config: Batch—e.g., aws kinesis put-records --records ... (500 max)—Tags—e.g., env=prod—Limits: 10,000 shards/stream, 5 consumers/shard (non-EFO), 20 (EFO)—soft limits.
Pricing
Data Streams: Provisioned—$0.015/shard-hour—e.g., 10 shards = $3.60/day—On-Demand—$0.037/GB ingested—PUTs—$0.0143/1M—Enhanced Fan-Out—$0.013/GB + $0.015/consumer-hour—Extended Retention—$0.02/GB-month—e.g., 7d for 1 TB = $20. Data Firehose: $0.029/GB processed—e.g., 1 TB = $29—Lambda—$0.20/1M invokes—Format Conversion—$0.018/GB. Data Analytics: $0.11/hour + $0.013/GB scanned—e.g., 1 app, 10 GB = $2.74/day. Video Streams: $0.016/min ingested—$0.0085/GB delivered—e.g., 1 hr 1 GB = $1.97. Free tier: None—starts at $0.36/day (1 shard). Example: 5 shards, 10M PUTs, 7d 1 TB, Firehose 1 TB = $81.54/day ($3.60 + $0.14 + $20 + $29 + $28.80 analytics).
Decoupling and Scaling
Scales via shards and consumers:
- Data Streams - Basic: 1 shard—e.g., logs at 1 MB/s—Lambda reads—1 GB/day.
- Intermediate: 10 shards—e.g., IoT 10 MB/s—KCL—e.g., 5 apps, DynamoDB leases—Retention—e.g., 7d—10 GB/hour.
- Advanced: 100 shards—e.g., 100 MB/s—Enhanced Fan-Out—e.g., 20 consumers, 400 MB/s total—On-Demand—e.g., auto-scale to 1 GB/s—1 TB/day.
- Data Firehose: Buffer—e.g., 1 TB to S3—Transform—e.g., Lambda adds
user_id—Redshift—e.g., 100 GB loaded—scales to 5,000 PUTs/sec.
Example: Clickstream—clicks-stream (50 shards, 50 MB/s), Firehose to S3 (transformed), Analytics (counts/min)—scales to 1M events/sec.
Use Cases and Scenarios
Data Streams: Logs—e.g., app logs to Lambda—IoT—e.g., 1M devices—Metrics—e.g., real-time dashboards. Data Firehose: ETL—e.g., logs to S3—Redshift—e.g., analytics sink—HTTP—e.g., 3rd-party POST. Data Analytics: Aggregates—e.g., AVG(value)—Alerts—e.g., value > 1000. Video Streams: Surveillance—e.g., live feed—Gaming—e.g., player streams.
Edge Cases and Gotchas
Data Streams: Shard Throttle—e.g., 1 MB/s in—2 MB/s exceeds—split via aws kinesis split-shard—Lag—e.g., 24h backlog—EFO or shard increase—KCL—e.g., lease contention—tune maxLeases. Data Firehose: Buffer Delay—e.g., 900s max—small data waits—force flush—Transform Fail—e.g., Lambda timeout—log to S3—Direct PUT—e.g., 5,000/sec limit—use Streams first. Data Analytics: 5 apps/stream—e.g., 6th fails—split streams—Window Skew—e.g., late data—adjust LATE_ARRIVAL. Video Streams: 5 Gbps/shard—e.g., 6 Gbps drops—add shards—HLS—e.g., 10s latency—tune chunk size. Cost: 1,000 shards—e.g., $360/day—On-Demand—e.g., $888/day for 24 TB—optimize.
Integration with Other Services
Lambda: Consumer—e.g., my-stream trigger—Firehose—e.g., transform. S3: Firehose—e.g., s3://my-bucket/—Analytics—e.g., output. Redshift: Firehose—e.g., COPY load—Analytics—e.g., sink. CloudWatch: Metrics—e.g., PutRecordThrottles—Logs—e.g., Lambda errors—Alarms—e.g., 80% shard usage. IAM: Access—e.g., {"Action": "kinesis:PutRecord"}. SNS/SQS: Alerts—e.g., Analytics → SNS on anomaly.
Overview
Amazon MQ, launched in 2017, is a managed message broker service supporting Apache ActiveMQ and RabbitMQ, enabling reliable, scalable messaging between applications using protocols like JMS, AMQP, MQTT, and STOMP. It decouples producers and consumers—e.g., an app sends orders to a queue, processed later by a worker—simplifying migrations from on-premises brokers without code rewrites. From basics (single-instance broker) to advanced (cross-region replication, RabbitMQ quorum queues), Amazon MQ scales to thousands of messages/sec, handling enterprise workloads with minimal ops overhead.
Architecture and Core Components
Amazon MQ is a regional, managed service—likely built on EC2 + storage layers (EFS/EBS)—orchestrating ActiveMQ or RabbitMQ instances. Key components:
- Broker: Message hub—e.g.,
my-broker—ActiveMQ (mq.m5.large) or RabbitMQ (mq.t3.micro), single-instance or active/standby. - Queue: Point-to-point—e.g.,
orders-queue—stores messages (256 KB max) until consumed. - Topic: Pub/sub—e.g.,
events-topic—broadcasts to multiple subscribers. - Storage: ActiveMQ—EFS (durability) or EBS (throughput)—RabbitMQ—EBS only—e.g., 20 GB/micro broker.
- Client: Producer/consumer—e.g., app via JMS to
my-broker.activemq.amazonaws.com.
Single-instance runs in one AZ—e.g., us-east-1a—active/standby spans AZs—e.g., 1a + 1b—with failover in ~1m. Messages replicate across AZs—99.9% SLA—cross-region replication (ActiveMQ) async to another region.
Features and Configuration
Basics: Create—e.g., aws mq create-broker --broker-name my-broker --engine-type ACTIVEMQ --engine-version 5.17.6 --instance-type mq.t3.micro—Connect—e.g., JMS to ssl://b-1234-5678-90ab.mq.us-east-1.amazonaws.com:61617—List—e.g., aws mq list-brokers. Intermediate: ActiveMQ—e.g., JMS, STOMP—RabbitMQ—e.g., AMQP 0-9-1, quorum queues—Deployment—e.g., active/standby via --deployment-mode ACTIVE_STANDBY_MULTI_AZ—Storage—e.g., 200 GB EBS—Users—e.g., aws mq create-user. Advanced: Cross-Region Replication (CRDR)—e.g., aws mq create-broker --replication-user ...—failover via aws mq reboot-broker—RabbitMQ Clusters—e.g., 3-node mq.m5.large—Network of Brokers—e.g., ActiveMQ mesh—Encryption—e.g., KMS at rest, TLS in transit—VPC—e.g., private endpoint—Maintenance—e.g., aws mq update-broker --maintenance-window-start-time "wed:03:00". Config: Protocols—e.g., MQTT, WebSocket—Logs—e.g., audit to CloudWatch—Limits: 20 GB (micro), 200 GB (others), 100 brokers—soft limits.
Pricing
Brokers: Single-instance—e.g., mq.t3.micro $0.048/hr ($34.56/month)—Active/Standby—e.g., mq.m5.large $0.576/hr ($428.54/month)—RabbitMQ Cluster—e.g., 3x mq.m5.large = $1,285.62/month. Storage: EFS—$0.30/GB-month—EBS—$0.10/GB-month—e.g., 100 GB EBS = $10/month. Data Transfer: AZ replication—$0.01/GB—Cross-region—$0.10/hr/broker—e.g., 744h = $148.80/month. Free tier: 750h mq.t3.micro, 5 GB EFS (ActiveMQ) or 20 GB EBS (RabbitMQ)—1 year. Example: Active/Standby mq.m5.large, 100 GB EBS, CRDR = $587.34/month ($428.54 + $10 + $148.80).
Decoupling and Scaling
Scales via broker size and config:
- Basic: Single
mq.t3.micro—e.g., 100 messages/sec, JMS app to queue—1 GB/day. - Intermediate: Active/Standby
mq.m5.large—e.g., 1,000 messages/sec, MQTT IoT—RabbitMQ cluster—e.g., 3 nodes—10 GB/hour. - Advanced: Network of Brokers—e.g., 5
mq.m5.xlarge, 10K messages/sec—CRDR—e.g., us-east-1 to us-west-2—Quorum—e.g., RabbitMQ HA—100 GB/day.
Example: Order system—orders-broker (Active/Standby, ActiveMQ), queues to workers, topics to alerts—scales to 1M messages/day with CRDR backup.
Use Cases and Scenarios
Basic: Task queue—e.g., app → work-queue → EC2. Migration: On-prem ActiveMQ—e.g., JMS endpoints swapped—RabbitMQ—e.g., AMQP apps. HA: Active/Standby—e.g., failover for finance—Cluster—e.g., RabbitMQ for IoT. Hybrid: CRDR—e.g., prod in us-east-1, DR in us-west-2.
Edge Cases and Gotchas
Storage: Fixed—e.g., 20 GB/micro—overflow halts—monitor HeapMemoryUsage—Scale—e.g., mq.m5.large for 200 GB. Failover: ~1m delay—e.g., active/standby—app reconnect logic needed—CRDR—e.g., async lag, manual failover. RabbitMQ: Quorum—e.g., 3 nodes min—split-brain—e.g., network partition—tune replication. Cost: Cluster—e.g., 3x mq.m5.xlarge = $2,571/month—CRDR—e.g., $148.80/month—optimize size. Protocols: MQTT—e.g., 10K clients—test limits—AMQP 1.0—e.g., ActiveMQ only—check compatibility.
Integration with Other Services
EC2: Agent—e.g., JMS client—Workers—e.g., poll queues. Lambda: Trigger—e.g., poll via MQ API (not direct). S3: Logs—e.g., s3://mq-logs/—Data—e.g., queue backups. CloudWatch: Metrics—e.g., QueueDepth—Logs—e.g., audit—Alarms—e.g., 80% storage. IAM: Access—e.g., {"Action": "mq:CreateBroker"}—Users—e.g., broker auth. VPC: Private—e.g., subnet-123...—SG—e.g., port 61617—KMS—e.g., encrypt EBS.
More
Additional AWS services for infrastructure automation, systems management, multi-account governance, machine learning, security, and disaster recovery.
Overview
AWS CloudFormation, launched in 2011, is an infrastructure-as-code (IaC) service that automates provisioning and management of AWS resources via templates (JSON/YAML). It ensures repeatable, consistent deployments—e.g., VPCs, EC2, S3—across accounts and regions. From basics (single EC2 stack) to advanced (nested stacks, drift detection), CloudFormation decouples infrastructure from manual ops, scaling to thousands of resources with declarative precision.
Architecture and Core Components
CloudFormation is a regional service—likely a state machine + API—executing templates to orchestrate AWS APIs. Key components:
- Template: Blueprint—e.g.,
template.yaml—defines resources (e.g.,AWS::EC2::Instance), parameters, outputs. - Stack: Deployment—e.g.,
my-stack—live instance of a template, manages resource lifecycle. - Resource: AWS entity—e.g.,
MyEC2—mapped to API calls (create, update, delete). - Change Set: Preview—e.g.,
aws cloudformation create-change-set—shows updates before applying. - Stack Set: Multi-account/region—e.g., deploy
my-stackto 10 accounts.
Flow: Template → Stack → API calls—e.g., CreateStack spins up EC2, S3—state stored in AWS (S3 + DynamoDB?). Rollback on failure—e.g., deletes partial resources—99.9% SLA.
Features and Configuration
Basics: Template—e.g., Resources: { MyEC2: { Type: 'AWS::EC2::Instance', Properties: { InstanceType: 't2.micro' } } }—Create—e.g., aws cloudformation create-stack --stack-name my-stack --template-body file://template.yaml—List—e.g., aws cloudformation describe-stacks. Intermediate: Parameters—e.g., InstanceType: { Type: String, Default: 't2.micro' }—Outputs—e.g., EC2DNS: !GetAtt MyEC2.PublicDnsName—Update—e.g., aws cloudformation update-stack—Deletion—e.g., aws cloudformation delete-stack. Advanced: Nested Stacks—e.g., AWS::CloudFormation::Stack for VPC + EC2—Drift Detection—e.g., aws cloudformation detect-stack-drift—Stack Sets—e.g., aws cloudformation create-stack-set—Custom Resources—e.g., Lambda-backed MyCustom::Type—Macros—e.g., transform YAML. Config: Roles—e.g., arn:aws:iam::123456789012:role/CFExecutionRole—Timeouts—e.g., 30m. Limits: 200 resources/stack, 500 stacks—soft limits.
Pricing
CloudFormation: Free—charges only for resources—e.g., EC2 $0.008/hr, no CF cost. Stack Sets: Free—multi-account orchestration. Custom Resources: Lambda—e.g., $0.20/1M invocations. Free tier: None—$0 unless resources provisioned. Example: Stack with 1 EC2 ($0.008/hr), 1 S3 ($0.023/GB-month) = $5.76/month + $0 CF.
Automation and Scaling
Scales to thousands of resources:
- Basic: Single stack—e.g., 1 EC2, 1 S3—
aws cloudformation deploy—10 resources. - Intermediate: Parameterized—e.g.,
t3.largevs.t2.micro—Nested—e.g., VPC + subnet stack—100 resources. - Advanced: Stack Sets—e.g., 50 accounts, 5 regions—Drift—e.g., fix manual changes—Custom—e.g., 1,000 Lambda-backed resources.
Example: App infra—app-stack (VPC, ALB, EC2 Auto Scaling)—nested network-stack—scales to 10K instances across regions.
Use Cases and Scenarios
Basic: Dev env—e.g., EC2 + S3. Prod Deploy: Multi-tier—e.g., VPC, RDS, ECS. DR: Stack Sets—e.g., replicate us-east-1 to us-west-2. Compliance: Drift—e.g., audit manual edits—Custom—e.g., enforce tags.
Edge Cases and Gotchas
Rollback: Fails—e.g., S3 bucket in use—manual cleanup—check StackStatus. Drift: Detect only—e.g., no auto-fix—script corrections. Limits: 200 resources—e.g., split large stacks—nested depth 100—e.g., 101 fails. Custom Resources: Lambda timeout—e.g., 15m—async needed—cost spikes—e.g., 1M calls = $200. Stack Sets: Throttle—e.g., 20 ops/sec—stagger deployments—role perms—e.g., missing iam:PassRole—fails silently.
Integration with Other Services
EC2: Instances—e.g., AWS::EC2::Instance. S3: Buckets—e.g., AWS::S3::Bucket. Lambda: Custom—e.g., AWS::CloudFormation::CustomResource. IAM: Roles—e.g., PassRole for CF. CloudWatch: Events—e.g., StackStatus CREATE_COMPLETE—Logs—e.g., CF ops. Systems Manager: Parameters—e.g., !Ref SSM::Parameter—Automation—e.g., post-deploy scripts.
Overview
AWS Systems Manager (SSM), launched in 2016 (formerly EC2 Systems Manager), is a suite of tools for managing and automating operations across AWS and on-premises resources—e.g., patching, config, scripts. It decouples ops from manual SSH/RDP, centralizing control for EC2, Lambda, or hybrid setups. From basics (Run Command) to advanced (State Manager, OpsItems), SSM scales to thousands of instances with zero infrastructure overhead.
Architecture and Core Components
SSM is a regional service—agent-based + serverless APIs—integrating with AWS’s control plane. Key components:
- SSM Agent: Daemon—e.g., on EC2—executes commands, sends自主> sends telemetry—pre-installed on AWS AMIs.
- Parameter Store: Config—e.g.,
/app/db/password—secure key-value storage. - Run Command: Remote exec—e.g.,
aws ssm send-command—runs scripts on instances. - State Manager: Compliance—e.g., enforce patching—applies docs periodically.
- Inventory: Metadata—e.g., OS version, apps—collected from agents.
Flow: Command → SSM API → Agent—e.g., AWS-RunShellScript → EC2—results to S3/CloudWatch. Hybrid support via Activation—e.g., on-prem VMs—99.9% SLA.
Features and Configuration
Basics: Run Command—e.g., aws ssm send-command --document-name AWS-RunShellScript --targets Key=tag:Env,Values=Prod --parameters commands='uptime'—Parameter—e.g., aws ssm put-parameter --name /app/key --value secret --type SecureString. Intermediate: Session Manager—e.g., aws ssm start-session --target i-1234567890abcdef0—no SSH—Patch Manager—e.g., AWS-RunPatchBaseline—Inventory—e.g., aws ssm list-inventory. Advanced: State Manager—e.g., aws ssm create-association --name AWS-UpdateSSMAgent—Automation—e.g., aws ssm start-automation-execution --document-name AWS-StopEC2Instance—OpsItems—e.g., aws ssm create-ops-item --title "Disk Full"—Distributor—e.g., deploy custom pkgs. Config: IAM—e.g., ssm:SendCommand—Encryption—e.g., KMS—Hybrid—e.g., aws ssm create-activation. Limits: 10,000 instances/doc, 1M parameters—soft limits.
Pricing
Core: Free—e.g., Run Command, Session Manager—$0. Parameter Store: Standard—free—Advanced—$0.05/10K API calls, $0.05/parameter-month—e.g., 1K advanced = $0.05/month. Automation: Free—resource costs apply—e.g., Lambda $0.20/1M. Distributor: $0.01/pkg-month—e.g., 10 pkgs = $0.10/month. Free tier: 10K Parameter Store calls, 1K advanced parameters—forever. Example: 100 instances, 1K advanced params, 10K calls = $0.10 ($0 + $0.05 + $0.05).
Automation and Scaling
Scales to thousands of instances:
- Basic: Run Command—e.g.,
uptimeon 10 EC2—Parameter—e.g.,/app/db—100 instances. - Intermediate: Session—e.g., interactive shell—Patch—e.g., 500 instances—Inventory—e.g., app versions—1K instances.
- Advanced: State—e.g., enforce config—Automation—e.g., stop 10K instances—OpsItems—e.g., auto-ticket—10K hybrid.
Example: Prod fleet—patch-prod (500 EC2 patched), /app/secrets (Parameter Store), Automation (restart on failure)—scales to 100K instances.
Use Cases and Scenarios
Basic: Scripts—e.g., df -h on EC2. Config: Parameter—e.g., DB creds—Patch—e.g., monthly updates. Ops: Session—e.g., debug instance—Automation—e.g., reboot failed. Hybrid: On-prem—e.g., manage VMs—OpsItems—e.g., incident response.
Edge Cases and Gotchas
Agent: Offline—e.g., no internet—fails commands—install manually—Version—e.g., <2.3—misses features—update via State. Parameter Cost: 1M advanced—e.g., $50/month—use standard where possible. Session: No SSH—e.g., port 22 closed—policy—e.g., ssm:StartSession missing—fails. Automation: Loops—e.g., infinite restart—set max attempts—Throttle—e.g., 1K/sec limit—stagger. Inventory: Lag—e.g., 15m sync—force refresh.
Integration with Other Services
EC2: Agent—e.g., i-123... target. Lambda: Automation—e.g., invoke on failure. S3: Output—e.g., s3://ssm-logs/. CloudWatch: Logs—e.g., command output—Events—e.g., patch triggers. IAM: Permissions—e.g., ssm:SendCommand. CloudFormation: Params—e.g., !Ref SSM::Parameter—Post-deploy—e.g., AWS-RunShellScript.
Overview
AWS Organizations, launched in 2017, is a service for centrally managing multiple AWS accounts—e.g., grouping accounts for billing, access, and compliance. It enables hierarchical organization via Organizational Units (OUs) and enforces policies, notably Service Control Policies (SCPs) for IAM policy evaluation. From basics (account creation) to advanced (SCP inheritance, policy evaluation logic), Organizations scales to thousands of accounts with governance at its core.
Architecture and Core Components
Organizations is a global, serverless service—likely a control plane over IAM and account metadata—managing a hierarchy rooted at a management account. Key components:
- Management Account: Root—e.g.,
admin@company.com—owns the organization. - Member Account: Sub-account—e.g.,
dev@company.com—linked to the org. - OU: Group—e.g.,
DevOU—nests accounts or OUs for structure. - SCP: Policy—e.g.,
{"Deny": {"Action": "s3:DeleteBucket"}}—restricts IAM permissions. - Root: Top—e.g.,
r-1234—base of the hierarchy.
Policy evaluation flows: SCPs → IAM → Resource Policies—effective permissions are the intersection—99.9% SLA—account isolation ensures security.
Features and Configuration
Basics: Create—e.g., aws organizations create-organization --feature-set ALL—Invite—e.g., aws organizations invite-account-to-organization --target Id=123456789012—List—e.g., aws organizations list-accounts. Intermediate: OU—e.g., aws organizations create-organizational-unit --parent-id r-1234 --name DevOU—Move—e.g., aws organizations move-account --account-id 123456789012 --destination-parent-id ou-5678—Tag—e.g., aws organizations tag-resource --resource-id ou-5678 --tags Key=env,Value=dev. Advanced: SCP—e.g., aws organizations create-policy --content '{"Version": "2012-10-17", "Statement": {"Effect": "Deny", "Action": "ec2:RunInstances"}}' --name DenyEC2 --type SERVICE_CONTROL_POLICY—Attach—e.g., aws organizations attach-policy --policy-id p-9012 --target-id ou-5678—Enable—e.g., aws organizations enable-aws-service-access --service-principal config.amazonaws.com—Limits: 1,000 accounts, 10 OU levels—soft limits.
IAM Policy Evaluation Details
SCP Basics: SCPs act as a guardrail—e.g., Deny s3:DeleteBucket—applied to OUs or accounts, overriding IAM allow unless explicitly denied. They don’t grant permissions—only filter—e.g., IAM allows s3:*, SCP denies s3:DeleteBucket, result: all S3 except delete. Intermediate: Inheritance—e.g., Root SCP (Deny ec2:*) + OU SCP (Allow ec2:Describe*) = only describe allowed—Explicit Deny—e.g., SCP deny always wins over IAM allow—Management Account—e.g., exempt from SCPs unless applied to root. Advanced: Evaluation Logic—e.g., effective permission = IAM ∩ SCP ∩ Resource Policy—e.g., IAM s3:* + SCP Deny s3:Delete* + Bucket Policy Allow s3:Get* = only s3:Get*—Tag Policies—e.g., aws organizations create-policy --type TAG_POLICY --content '{"tags": {"env": {"required": true}}}'—Cross-Service—e.g., Config/CloudTrail integration—Debug—e.g., aws sts get-caller-identity + IAM simulator—Limits: 10 SCPs/target—soft limit.
Pricing
Base: Free—core features (OUs, SCPs, account management). Consolidated Billing: Free—aggregates usage—e.g., 100 accounts = $0. Extras: Costs from integrated services—e.g., CloudTrail ($2/100K events), Config ($0.003/resource)—no direct Organizations fee. Free tier: Full service—forever. Example: 1,000 accounts, 10 SCPs, 1M CloudTrail events = $20/month (all from CloudTrail).
Management and Scaling
Scales with accounts:
- Basic: 5 accounts—e.g., prod/dev—SCP—e.g., deny S3 deletes—10K API calls/month.
- Intermediate: 100 accounts—e.g., multi-dept—OU—e.g., Dev/Test/Prod—SCP inheritance—100K API calls/month.
- Advanced: 1,000 accounts—e.g., enterprise—Tag Policies—e.g., enforce tagging—Cross-Service—e.g., Config rules—1M API calls/month.
Example: Enterprise—my-org (1K accounts), OUs (Dev/Prod), SCPs (restrict EC2)—scales to 10K accounts.
Use Cases and Scenarios
Basic: Billing—e.g., consolidate costs—Access—e.g., group accounts. Intermediate: Governance—e.g., SCP deny risky actions—OU—e.g., sandbox vs. prod. Advanced: Compliance—e.g., enforce encryption—Tag—e.g., cost allocation—Multi-Account—e.g., DR setup.
Edge Cases and Gotchas
SCP: No grant—e.g., SCP Allow s3:Get* doesn’t enable without IAM—Deny wins—e.g., OU SCP overrides root allow—Management—e.g., SCP-free—test carefully. Inheritance: Overlap—e.g., conflicting SCPs—check hierarchy—Detach—e.g., SCP lingers—re-apply root. Cost: Indirect—e.g., 1B CloudTrail events = $20K—limit logging—Scale—e.g., 10K accounts—request quota. Evaluation: Complexity—e.g., SCP + IAM + Resource Policy—use simulator—Latency—e.g., SCP apply ~1m—plan delays.
Integration with Other Services
IAM: Policies—e.g., SCP filters—STS—e.g., assume-role—S3: Billing—e.g., cost reports—CloudTrail: Audit—e.g., Org events. Config: Compliance—e.g., rules across accounts—CloudWatch: Metrics—e.g., AWSOrganizationsAccounts—SSM: Automation—e.g., account setup—RAM: Sharing—e.g., VPC subnets.
Amazon Rekognition
Amazon Rekognition is a managed computer vision service for analyzing images and videos—e.g., detecting faces, objects, or text. It powers use cases like content moderation, facial recognition, and video analytics with pre-trained models, scaling to millions of media files effortlessly.
Amazon Transcribe
Amazon Transcribe is an automatic speech recognition (ASR) service that converts audio to text—e.g., transcribing podcasts or meetings. It supports real-time and batch processing, speaker identification, and custom vocabularies, ideal for accessibility and analytics.
Amazon Polly
Amazon Polly is a text-to-speech (TTS) service that generates lifelike audio from text—e.g., voiceovers for apps or e-learning. It offers multiple voices, languages, and neural voices for natural-sounding speech, perfect for customer engagement.
Amazon Translate
Amazon Translate is a neural machine translation service for converting text between languages—e.g., English to Spanish. It delivers fast, accurate translations for apps, websites, or documents, supporting real-time and batch workflows with customization options.
Amazon Lex
Amazon Lex is a conversational AI service for building chatbots and voice interfaces—e.g., customer support bots. It uses ASR and natural language understanding (NLU) from Alexa tech, enabling intent recognition and multi-turn dialogues.
Amazon Comprehend
Amazon Comprehend is a natural language processing (NLP) service for extracting insights from text—e.g., sentiment, entities, or topics. It powers text analytics for reviews, documents, or social media with pre-trained or custom models.
Amazon SageMaker
Amazon SageMaker is a comprehensive ML platform for building, training, and deploying models—e.g., predictive analytics or image classification. It offers Jupyter notebooks, managed training, and inference endpoints, supporting end-to-end ML workflows at scale.
Amazon Kendra
Amazon Kendra is an intelligent search service powered by ML—e.g., enterprise document search. It uses NLP to understand queries, index content from S3, databases, or apps, and return precise answers, boosting productivity.
Amazon Personalize
Amazon Personalize is a real-time recommendation service—e.g., product suggestions or content curation. It leverages ML to analyze user behavior and deliver personalized experiences, integrating easily with apps or websites.
Amazon Textract
Amazon Textract is an OCR and document analysis service for extracting text and data—e.g., forms, invoices, or PDFs. It identifies tables, key-value pairs, and handwriting, automating data entry and document processing.
AWS Key Management Service (KMS)
Overview
AWS Key Management Service (KMS), introduced in 2014, stands as a cornerstone for cryptographic operations within AWS, empowering users to create, manage, and control encryption keys with ease and precision. Whether it’s safeguarding sensitive data in S3 buckets, securing EBS volumes, or encrypting RDS databases, KMS integrates seamlessly with over 100 AWS services, offering a unified approach to encryption at rest and in transit. Built on the robust foundation of FIPS 140-3 Level 3 Hardware Security Modules (HSMs), KMS ensures that keys remain protected within a highly secure environment, never leaving unencrypted—a critical feature for compliance-driven industries like finance and healthcare. It supports both symmetric keys (e.g., AES-256 for broad encryption needs) and asymmetric key pairs (e.g., RSA or ECC for signing and verification), providing flexibility for diverse use cases. KMS scales effortlessly to handle billions of cryptographic operations, making it a go-to solution for enterprises managing vast datasets or developers securing small-scale applications, all while centralizing key lifecycle management—creation, rotation, and deletion—under a single pane of glass.
Architecture and Core Components
KMS operates as a regional service, leveraging a distributed cluster of HSMs to generate and store keys in an encrypted state. Core components include the KMS Key (e.g., arn:aws:kms:us-east-1:123:key/abc), serving as the root key for encryption tasks; the Data Key, generated on-demand for envelope encryption to protect data outside KMS; and the HSM, ensuring keys are never exposed unencrypted. The workflow is straightforward: an application calls KMS to encrypt or decrypt, with operations executed securely within the HSM boundary—backed by a 99.99% SLA and 11 9’s durability through redundant backups.
Use Cases
Encrypting S3 objects with server-side encryption (SSE-KMS)—e.g., securing customer data; protecting EBS volumes—e.g., snapshot encryption for backups; securing RDS instances—e.g., database encryption for compliance.
Edge Cases
Key deletion delays—e.g., a mandatory 7-day waiting period complicates rapid key removal; throttling—e.g., hitting 10K requests/sec requires careful rate limiting; cross-account usage—e.g., granting permissions can lead to access mismatches if misconfigured.
KMS Multi-Region Keys
Overview
Launched in 2020, KMS Multi-Region Keys extend the power of KMS by enabling key replication across AWS regions—think us-east-1 to eu-west-1—to deliver high availability, reduced latency, and resilience for globally distributed applications. Imagine a multinational company needing consistent encryption for S3 buckets replicated across continents or a disaster recovery setup requiring immediate failover without key regeneration: Multi-Region Keys make this possible. Each key, identified by a shared multi-region key ID (e.g., mrk-123), functions as an independent entity in its region, yet ties back to a primary key, offering flexibility in management—rotate in one region, and replicas follow suit with manual sync. This feature shines in scenarios where data sovereignty demands local encryption but global consistency is non-negotiable, all while leaning on KMS’s HSM-backed security to ensure keys remain untouchable. It’s a game-changer for enterprises juggling compliance across borders or developers building latency-sensitive, encrypted workflows.
Architecture
The architecture centers on a primary key (e.g., in us-east-1) with replicas (e.g., in eu-west-1), linked by a common key ID. Each replica is managed independently—rotation or policy changes in one region don’t auto-sync—stored in regional HSMs with a 99.99% SLA, ensuring cryptographic operations stay local yet consistent.
Use Cases
Global S3 replication—e.g., encrypting data in multiple regions for a content delivery network; disaster recovery—e.g., failover encryption for multi-region resilience.
Edge Cases
Replica synchronization lag—e.g., policy updates may delay across regions; S3 compatibility—e.g., replication treats multi-region keys as single-region, requiring careful configuration.
S3 Replication with Encryption
Overview
S3 Replication with Encryption brings a robust mechanism to copy objects between S3 buckets—whether across regions (CRR, like us-east-1 to us-west-2) or within the same region (SRR)—while ensuring data remains encrypted using options like SSE-S3 (AWS-managed) or SSE-KMS (custom KMS keys). This isn’t just about moving data; it’s about securing it for backup, compliance, or latency optimization in a world where data breaches are a constant threat. Picture a company mirroring sensitive customer records to a backup region for disaster recovery or a media firm replicating encrypted video assets closer to users—all handled asynchronously with near-instant setup. With support for Replication Time Control (RTC) to meet tight SLAs (e.g., 15 minutes), it scales to billions of objects, marrying S3’s durability with KMS’s encryption prowess. It’s a lifeline for organizations needing to meet data residency laws or maintain uptime amidst regional outages, all while keeping data locked tight.
Architecture
The process flows from a source bucket to a destination bucket via a replication rule, with encryption applied using SSE-S3 (default AES-256) or SSE-KMS (custom key). It’s asynchronous, backed by a 99.99% SLA, and integrates with S3 Events for notifications and CloudWatch for monitoring replication status.
Use Cases
Disaster recovery—e.g., encrypted backups across regions; compliance—e.g., ensuring data residency with encrypted copies in specific locales.
Edge Cases
KMS region mismatch—e.g., replication fails if the KMS key’s region doesn’t align with the bucket; replication lag—e.g., RTC failures under heavy load or network issues.
Encrypted AMI Sharing Process
Overview
The Encrypted AMI Sharing Process transforms how organizations securely distribute Amazon Machine Images (AMIs) backed by encrypted EBS snapshots—think sharing a hardened server image with a partner account or publishing to the AWS Marketplace. Introduced to meet stringent security needs, this process ensures that an AMI, encrypted with a KMS key, can be shared across accounts or even publicly while preserving its encrypted state, a must for compliance-heavy sectors like government or healthcare. It starts with creating an encrypted EBS snapshot, ties it to an AMI, and then grants access—both to the snapshot and the KMS key—to the target account, enabling them to launch instances without ever exposing plaintext data. This isn’t just a technical handshake; it’s a secure bridge for collaboration, disaster recovery, or commercial distribution, scaling effortlessly as teams grow or markets expand, all while leaning on AWS’s encryption backbone to keep sensitive configurations safe.
Architecture
The AMI links to an encrypted EBS snapshot, secured by a KMS key. Sharing involves granting permissions to the snapshot and a KMS grant to the target account, allowing EC2 to launch instances—backed by a 99.9% SLA for snapshot durability.
Use Cases
Cross-account disaster recovery—e.g., sharing encrypted AMIs for rapid recovery; vendor sharing—e.g., distributing secure AMIs via the AWS Marketplace.
Edge Cases
Key revocation—e.g., revoking the KMS key breaks instance launches; permission mismatches—e.g., forgetting the KMS grant stalls access.
SSM Parameter Store
Overview
SSM Parameter Store, nestled within AWS Systems Manager, offers a deceptively simple yet powerful way to manage configuration data and secrets—like database credentials, API keys, or app settings—across sprawling AWS environments. It’s more than a key-value store; it’s a secure vault that scales to thousands of parameters, supporting both plaintext (e.g., a public URL) and encrypted SecureString types backed by KMS for sensitive data. Picture a DevOps team juggling credentials across dev, test, and prod environments: Parameter Store organizes these into a hierarchical structure (e.g., /prod/db/password), making retrieval a breeze while keeping secrets locked tight. Launched as part of SSM’s broader toolkit, it’s become a go-to for developers and sysadmins who need centralized, auditable config management without the overhead of a full secrets service, all while integrating with IAM for fine-grained access control and KMS for bulletproof encryption.
Architecture
Parameters are stored in a DynamoDB-like backend, with SecureString types encrypted via KMS. Access occurs through the SSM API, with decryption handled on-the-fly—secured by a 99.9% SLA.
Use Cases
Application configuration—e.g., storing database credentials securely; secret management—e.g., encrypted API tokens for microservices.
Edge Cases
KMS dependency—e.g., a KMS outage blocks SecureString decryption; quota limits—e.g., hitting 10K parameters requires planning or quota increases.
AWS Secrets Manager
Overview
AWS Secrets Manager, unveiled in 2018, takes secret management to the next level, offering a purpose-built solution for storing, retrieving, and rotating sensitive data like database passwords, API keys, or OAuth tokens. Unlike Parameter Store’s broader config focus, Secrets Manager is laser-focused on secrets, providing automatic rotation—imagine a MySQL password updating every 30 days without manual intervention—backed by Lambda functions and KMS encryption. It’s designed for security-first teams who need to scale to thousands of secrets across complex applications, offering a higher-level abstraction than Parameter Store with features like built-in auditing and cross-account access. Whether it’s a SaaS app fetching rotating API keys or an enterprise ensuring HIPAA compliance, Secrets Manager delivers a seamless, secure experience, integrating with services like RDS and Redshift to simplify credential lifecycle management while keeping prying eyes out.
Architecture
Secrets are stored in a secure backend, encrypted with KMS, and managed via the Secrets Manager API. Rotation leverages Lambda triggers, ensuring seamless updates—backed by a 99.9% SLA.
Use Cases
Database credentials—e.g., auto-rotating RDS passwords; API keys—e.g., secure retrieval for third-party integrations.
Edge Cases
Rotation failures—e.g., a misconfigured Lambda stalls updates; high secret volume—e.g., managing thousands can complicate auditing.
AWS Certificate Manager (ACM)
Overview
AWS Certificate Manager (ACM), launched in 2016, simplifies the messy world of SSL/TLS certificates, providing a free, managed solution for securing web traffic—think HTTPS for CloudFront distributions or Application Load Balancers. It’s a lifeline for developers and admins who dread certificate renewals, as ACM handles issuance, deployment, and auto-renewal with zero fuss, all tied to AWS’s trusted Certificate Authority (CA). Beyond public certificates, it offers a Private CA option for internal TLS needs—perfect for microservices or on-premises hybrids—making it a versatile tool for organizations of all sizes. Whether you’re a startup securing a single domain or an enterprise managing a fleet of internal APIs, ACM ensures encrypted connections without the headache of manual cert juggling, scaling effortlessly as your infrastructure grows.
Architecture
ACM interfaces with an AWS-managed CA to issue certificates, stored securely and deployed to integrated services like ELB or CloudFront—backed by a 99.9% SLA.
Use Cases
HTTPS enforcement—e.g., securing CloudFront distributions; internal TLS—e.g., Private CA for microservices.
Edge Cases
Renewal failures—e.g., DNS validation issues halt auto-renew; export limitations—e.g., public certs can’t be exported for external use.
AWS WAF
Overview
AWS Web Application Firewall (WAF), rolled out in 2015, acts as a digital shield for web applications, protecting against common threats like SQL injection, cross-site scripting (XSS), and DDoS attacks—whether they’re running on CloudFront, ALB, or API Gateway. It’s not just a filter; it’s a customizable gatekeeper, letting you define rules to block malicious traffic—say, an IP spamming requests—or allow legitimate users through, all while scaling to handle millions of requests per second. Think of a retail site fending off bots during a sale or a content platform blocking script kiddies: WAF’s got it covered with managed rule sets (e.g., OWASP Top 10) and the flexibility to craft your own. It’s a critical layer for anyone exposing apps to the wild internet, offering real-time protection with minimal latency.
Architecture
WAF inspects incoming traffic via rules, integrated with CloudFront/ALB, deciding to block or allow based on conditions—backed by a 99.9% SLA.
Use Cases
XSS protection—e.g., filtering malicious scripts; rate limiting—e.g., mitigating bot traffic on APIs.
Edge Cases
False positives—e.g., overly strict rules block legit users; rule complexity—e.g., managing hundreds can slow performance.
AWS Shield
Overview
AWS Shield, introduced in 2016, is your first line of defense against Distributed Denial of Service (DDoS) attacks, safeguarding resources like CloudFront, Route 53, and ELB from overwhelming traffic floods. It comes in two flavors: Shield Standard, a free, always-on service that tackles common Layer 3/4 attacks (e.g., SYN floods), and Shield Advanced, a paid tier that ramps up protection with Layer 7 mitigation, cost protection, and access to AWS’s DDoS Response Team (DRT). Imagine a gaming platform under attack during a launch or a news site hit by a botnet: Shield scales to absorb terabits-per-second assaults, keeping services online. It’s built for resilience, blending edge-level filtering with deep packet inspection, making it a must-have for public-facing apps in a threat-heavy world.
Architecture
Shield operates at AWS’s edge, detecting and mitigating DDoS traffic—Standard is automatic, while Advanced integrates DRT and WAF—backed by a 99.9% SLA.
Use Cases
DDoS mitigation—e.g., blocking SYN floods on CloudFront; cost protection—e.g., Advanced covers spike-related charges.
Edge Cases
Standard limits—e.g., no Layer 7 protection; Advanced complexity—e.g., setup requires WAF integration for full coverage.
AWS Firewall Manager
Overview
AWS Firewall Manager, launched in 2018, steps up as a centralized command center for security policies, orchestrating tools like WAF, Shield Advanced, and VPC security groups across multiple accounts and resources via AWS Organizations. It’s the glue for enterprises managing sprawling environments—think a global firm enforcing consistent WAF rules across 50 accounts or a compliance team locking down VPCs with uniform NACLs. Rather than tweaking rules account-by-account, Firewall Manager lets you define policies once and apply them everywhere, scaling to thousands of resources without breaking a sweat. It’s a governance powerhouse, ensuring security stays tight and auditable, especially in regulated industries where consistency isn’t optional but mandatory.
Architecture
Firewall Manager leverages Organizations to distribute policies (e.g., WAF rules, Shield protections) across accounts and resources—backed by a 99.9% SLA.
Use Cases
Multi-account WAF—e.g., enforcing consistent rules across an Org; VPC security—e.g., standardizing NACLs for compliance.
Edge Cases
Organizations dependency—e.g., useless without an Org setup; policy conflicts—e.g., local overrides can disrupt uniformity.
Amazon GuardDuty
Overview
Amazon GuardDuty, launched in 2017, is a sharp-eyed sentinel for your AWS environment, using machine learning and anomaly detection to spot threats—think compromised IAM credentials or unusual VPC traffic—by analyzing CloudTrail, VPC Flow Logs, and DNS logs. It’s like having a security analyst who never sleeps, sifting through billions of events to flag malicious activity, from crypto-mining attempts to reconnaissance scans. Designed for simplicity, it activates with a single click and scales effortlessly, making it a fit for startups watching a handful of resources or enterprises guarding a global footprint. GuardDuty doesn’t just detect; it delivers actionable findings, integrating with EventBridge or Lambda to kick off responses, offering a proactive shield in a landscape where threats evolve daily.
Architecture
GuardDuty ingests logs (CloudTrail, VPC, DNS), processes them with ML and rules, and outputs findings—backed by a 99.9% SLA.
Use Cases
Account compromise—e.g., detecting IAM abuse; reconnaissance—e.g., identifying port scans in VPCs.
Edge Cases
False positives—e.g., benign anomalies flagged need tuning; log gaps—e.g., missing CloudTrail data limits visibility.
AWS Inspector
Overview
AWS Inspector, introduced in 2015, is your automated security auditor, scanning EC2 instances and container images for vulnerabilities—think unpatched CVEs or deviations from CIS benchmarks—across thousands of resources with minimal setup. It’s a lifeline for teams needing to prove compliance or harden workloads, offering both agent-based deep scans (e.g., software flaws) and agentless network checks (e.g., exposed ports). Picture a DevSecOps pipeline catching a critical patch before deployment or an auditor verifying a fleet meets PCI standards: Inspector delivers detailed findings to make that happen. It scales as your infrastructure grows, balancing thoroughness with simplicity, and integrates with CloudWatch for real-time alerts, making it a quiet but essential player in the security lineup.
Architecture
Inspector uses an optional agent on EC2 or scans container images, assessing against rules (e.g., CVEs) to produce findings—backed by a 99.9% SLA.
Use Cases
Vulnerability scanning—e.g., patching EC2 instances; compliance—e.g., validating CIS benchmarks.
Edge Cases
Agentless limitations—e.g., misses deep software flaws; scan frequency—e.g., manual triggers can lag behind threats.
Amazon Macie
Overview
Amazon Macie, launched in 2017, is a data security guardian, wielding machine learning and pattern matching to uncover sensitive data—like PII, financial records, or intellectual property—lurking in S3 buckets across petabytes of storage. It’s built for a world where data sprawl risks breaches or fines, helping organizations spot unsecured files (e.g., a CSV with SSNs) or misconfigured buckets before they become headlines. Think of a healthcare provider ensuring HIPAA compliance or a retailer auditing customer data: Macie scans, classifies, and alerts with precision, scaling to millions of objects without slowing down. It’s not just detection; it’s prevention, integrating with EventBridge to trigger fixes, offering a smart, proactive layer for data protection in an increasingly regulated cloud.
Architecture
Macie scans S3 buckets, uses ML and patterns to classify data, and generates findings—backed by a 99.9% SLA.
Use Cases
PII detection—e.g., finding leaks in S3 buckets; compliance—e.g., meeting GDPR or CCPA requirements.
Edge Cases
False positives—e.g., custom data types need manual patterns; scan scope—e.g., missing non-S3 data limits coverage.
AWS Database Migration Service (DMS)
Overview
AWS Database Migration Service (DMS), launched in 2016, is a versatile, managed solution designed to streamline the migration and replication of databases into and within the AWS ecosystem, minimizing disruption while maximizing security. Whether you’re moving an on-premises Oracle database to Amazon RDS, shifting a MySQL instance to Aurora, or replicating data from PostgreSQL to S3 for analytics, DMS handles it all with a focus on keeping source databases operational during the process. It excels in both homogeneous migrations—like Oracle to Oracle—and heterogeneous ones—like SQL Server to Aurora—supporting a broad range of commercial and open-source engines. Beyond one-time lifts, DMS shines in continuous replication, syncing changes with low latency to build resilient, multi-region data architectures or feed data lakes. Think of a retail chain migrating its legacy inventory system to the cloud with zero downtime or a financial firm consolidating analytics across regions—DMS simplifies these transitions by automating schema conversion, data movement, and ongoing synchronization, all while integrating with KMS for encryption and IAM for access control.
Architecture
DMS operates via a replication instance—an EC2-like server—bridging source and target endpoints. Data flows from the source (e.g., on-premises DB) to the instance, where it’s transformed if needed, then loaded into the target (e.g., RDS)—backed by a 99.9% SLA. It uses change data capture (CDC) for ongoing replication, ensuring near-real-time sync—encrypted in transit and at rest.
Use Cases
Database migration—e.g., lifting SQL Server to Aurora with minimal downtime; continuous replication—e.g., syncing on-premises MySQL to S3 for a data lake.
Edge Cases
CDC latency—e.g., high transaction volumes delay sync; schema mismatches—e.g., unsupported data types in heterogeneous moves require manual fixes.
RDS and Aurora Migrations
Overview
RDS and Aurora Migrations encompass the process of transitioning databases to Amazon Relational Database Service (RDS) or Aurora, AWS’s high-performance, managed database offerings, designed to offload the grunt work of database administration while boosting scalability and resilience. RDS supports engines like PostgreSQL, MySQL, Oracle, and SQL Server, providing a familiar platform for on-premises workloads—imagine a company moving its ERP system from a local Oracle instance to RDS for easier scaling. Aurora, a MySQL- and PostgreSQL-compatible powerhouse, takes it further with up to 5x performance over traditional engines and global database capabilities—perfect for a multinational needing low-latency reads across continents. Migrations leverage tools like DMS for data transfer, native backup/restore (e.g., mysqldump), or Aurora’s cloning for rapid setup, catering to everything from small dev databases to petabyte-scale enterprise systems. It’s about cutting downtime, enhancing HA, and freeing teams to focus on innovation rather than patching servers.
Architecture
RDS runs on managed EC2 instances with automated backups and Multi-AZ failover—99.95% SLA. Aurora separates compute (instances) from storage (shared across AZs), replicating data 6x for 11 9’s durability—global setups span regions with read replicas.
Use Cases
Lift-and-shift—e.g., moving on-premises PostgreSQL to RDS; global apps—e.g., Aurora global database for multi-region retail analytics.
Edge Cases
Downtime risks—e.g., large DBs using native tools need longer cutover; version mismatches—e.g., Aurora’s engine compatibility may miss some legacy features.
On-Premises Strategies
Overview
On-Premises Strategies for AWS migrations tackle the complex challenge of shifting workloads from legacy data centers to the cloud, blending tools and tactics to balance speed, cost, and continuity. This isn’t a one-size-fits-all game—options range from rehosting (lift-and-shift via MGN) to replatforming (e.g., DMS to Aurora) or refactoring for cloud-native designs. Picture a manufacturer with decades-old servers: they might start with discovery using AWS Application Discovery Service to map dependencies, then use Snowball to physically ship terabytes of data, followed by DMS for DBs and MGN for apps—keeping production humming throughout. Strategies also lean on hybrid setups—like VMware Cloud on AWS—to bridge on-prem and cloud, or AWS Outposts for low-latency local processing. It’s about de-risking the leap, ensuring compliance (e.g., HIPAA data stays encrypted), and paving the way for modernization without breaking the bank or the business.
Architecture
Hybrid setups connect on-prem via Direct Connect or VPN to AWS—data flows through Snowball or DataSync, apps via MGN, DBs via DMS—staged in VPCs with 99.9% SLA for key services.
Use Cases
Data center exit—e.g., moving legacy apps to EC2; hybrid DR—e.g., syncing on-prem DBs to RDS.
Edge Cases
Dependency blind spots—e.g., unmapped app links delay migration; bandwidth choke—e.g., slow internet stalls online transfers.
AWS Backup
Overview
AWS Backup is a centralized, fully managed service that simplifies protecting data across AWS services—think EBS volumes, RDS databases, S3 buckets, or even VMware workloads—with a few clicks, ensuring recovery from accidental deletions, ransomware, or outages. It’s the safety net for a cloud-first world, letting you define policies (e.g., daily snapshots, 30-day retention) and automate backups across accounts and regions—crucial for a company needing consistent DR across a global footprint. Beyond AWS-native resources, it extends to on-premises via VMware integration, bridging hybrid environments seamlessly. Imagine a healthcare provider safeguarding patient records in S3 or a startup restoring an RDS instance after a misstep—AWS Backup delivers point-in-time recovery with encryption baked in, scaling to petabytes without the overhead of custom scripts or third-party tools.
Architecture
Backup runs as a serverless control plane, orchestrating snapshots (EBS, RDS) or copies (S3) to vaults—encrypted via KMS, stored with 11 9’s durability—99.9% SLA for execution.
Use Cases
DR—e.g., restoring EBS after an outage; compliance—e.g., long-term S3 retention for audits.
Edge Cases
Restore delays—e.g., large snapshots take hours; cross-region lag—e.g., replication slows under network strain.
AWS Migration Hub (MGN)
Overview
AWS Migration Hub (MGN), evolved from CloudEndure in 2021, is a lift-and-shift powerhouse for moving applications to AWS with near-zero downtime, targeting physical servers, virtual machines, or other clouds—think VMware, Hyper-V, or Azure—into EC2 instances. It’s built for speed and simplicity: install an agent, replicate data continuously at the block level, and cut over when ready—perfect for a retailer shifting its POS system or a bank moving legacy apps without users noticing. MGN minimizes manual rework by auto-converting servers to run natively on AWS, supporting non-disruptive testing before the final flip. It’s the go-to for organizations needing to evacuate data centers fast or consolidateptoms multi-cloud sprawl, offering a unified dashboard to track progress and a low-friction path to cloud adoption.
Architecture
MGN uses agents on source servers to replicate data to a staging area (EC2 instances + EBS) in AWS—encrypted, continuous sync—then launches target instances—99.9% SLA for replication.
Use Cases
Server migration—e.g., VMware to EC2; DR testing—e.g., pre-cutover validation.
Edge Cases
Agent failures—e.g., incompatible OS blocks replication; cutover glitches—e.g., misconfigured launch settings fail instances.
Transferring Large Datasets into AWS
Overview
Transferring Large Datasets into AWS tackles the daunting task of moving terabytes—or petabytes—of data into the cloud, offering a suite of tools to match your bandwidth, timeline, and security needs. For massive hauls, AWS Snowball ships rugged, 80 TB devices to your site—load your data (e.g., archival records), ship it back, and it lands in S3—ideal for a media company offloading decades of footage. Snowmobile ups the ante with a truck hauling up to 100 PB, perfect for data center exits. For online moves, AWS DataSync accelerates transfers over Direct Connect—think a research lab syncing genomic data—or S3 Transfer Acceleration boosts uploads via edge locations. Each method encrypts data end-to-end, scaling to exabytes while dodging internet bottlenecks, ensuring fast, secure ingress for analytics, ML, or DR.
Architecture
Snowball/Snowmobile offloads to S3 via physical transport—11 9’s durability. DataSync uses agents to sync to S3/EFS over networks—99.9% SLA. Acceleration leverages CloudFront edges to S3.
Use Cases
Data migration—e.g., 50 TB of logs via Snowball; real-time sync—e.g., DataSync for research data.
Edge Cases
Shipping delays—e.g., Snowball transit slows migration; network throttling—e.g., DataSync hits bandwidth caps.
VMware Cloud on AWS
Overview
VMware Cloud on AWS, launched in 2017, bridges on-premises VMware environments to AWS, letting you run vSphere workloads natively in the cloud without refactoring—think of it as a hybrid superpower for enterprises with entrenched VMware stacks. It’s a fully managed service where AWS hosts VMware’s SDDC (vSphere, vSAN, NSX), connected via high-speed links to AWS services like S3 or RDS—perfect for a manufacturer extending its data center or a bank setting up DR. You keep your VMware tools (e.g., vCenter) while tapping AWS’s scale, spinning up hosts in minutes to migrate VMs, burst capacity, or recover from outages. Recent updates (as of 2025) include stretched clusters for zero-downtime DR and tighter integration with AWS Backup, making it a seamless pivot for VMware shops eyeing cloud benefits without a full overhaul.
Architecture
VMware SDDC runs on dedicated EC2 bare-metal instances, linked to AWS via ENI—VMs migrate via vMotion or HCX—99.9% SLA, tied to VPCs for hybrid access.
Use Cases
Data center extension—e.g., scaling VMware to AWS; DR—e.g., stretched clusters for failover.
Edge Cases
Cluster limits—e.g., max hosts constrain scale; latency—e.g., on-prem to AWS links slow vMotion.
Overview
AWS Storage Gateway, launched in 2011, is a hybrid cloud storage service that bridges on-premises environments with AWS cloud storage, enabling seamless data access, backup, and disaster recovery. It provides low-latency access to S3, Glacier, and EBS via virtual appliances—e.g., File, Volume, or Tape Gateway—deployed on-premises or in AWS. Whether it’s a company archiving decades of records to Glacier or syncing file shares to S3 for global teams, Storage Gateway simplifies hybrid workflows. From basics (file shares) to advanced (tiered backups, DR replication), it scales to petabytes, blending local performance with cloud economics.
Architecture and Core Components
Storage Gateway is a regional service with a gateway appliance (VM or hardware) connecting on-premises systems to AWS storage via APIs. Key components:
- File Gateway: NFS/SMB interface—e.g.,
s3://my-bucket—maps local files to S3 objects. - Volume Gateway: iSCSI block storage—e.g., cached or stored modes—backs to S3, snapshots to EBS.
- Tape Gateway: Virtual tape library (VTL)—e.g., iSCSI VTL—archives to S3, transitions to Glacier.
- Gateway Appliance: VM (VMware, Hyper-V, EC2) or hardware—e.g., SG1000—runs locally, syncs to AWS.
- Activation: Key—e.g.,
aws storagegateway activate-gateway—links gateway to AWS account.
Flow: Local writes → Gateway cache → Async upload to S3—e.g., File Gateway caches hot data, syncs to S3—state in DynamoDB/S3, 99.9% SLA.
Features and Configuration
Basics: File—e.g., aws storagegateway create-smb-file-share --gateway-arn arn:aws:storagegateway:us-east-1:123:gateway/sgw-123 --location-arn arn:aws:s3:::my-bucket—Volume—e.g., aws storagegateway create-cached-iscsi-volume—Tape—e.g., aws storagegateway create-tape-with-barcode. Intermediate: Cached Mode—e.g., 150 GiB local cache—Stored Mode—e.g., full local copy, S3 backup—Snapshots—e.g., aws storagegateway create-snapshot. Advanced: Bandwidth Throttling—e.g., 512 KBps cap—CloudWatch Metrics—e.g., CacheHitPercent—Lifecycle Policies—e.g., Glacier transitions—HA—e.g., multi-gateway sync. Config: IAM—e.g., storagegateway:UploadBuffer—Storage—e.g., 32 TiB max volume—Activation—e.g., IP-based. Limits: 150 volumes/gateway, 1 PB total—soft limits.
Pricing
Gateway: $0.01/hr—e.g., $7.30/month per gateway—$125 one-time for hardware appliance. Storage: S3—e.g., $0.023/GB-month—Glacier—e.g., $0.004/GB-month—EBS Snapshots—e.g., $0.05/GB-month. Data Transfer: Out—e.g., $0.09/GB—In—free—Requests—e.g., $0.005/1K PUTs. Free tier: None—$0 unless deployed. Example: File Gateway ($7.30/month) + 100 GB S3 ($2.30) + 10 GB out ($0.90) = $10.50/month.
Automation and Scaling
Scales to petabytes:
- Basic: Single gateway—e.g., 1 TB file share—
aws storagegateway refresh-cache—10 volumes. - Intermediate: Multi-gateway—e.g., 10 TB cached volumes—Snapshots—e.g., daily EBS backups—100 volumes.
- Advanced: HA—e.g., failover pairs—Lifecycle—e.g., 1 PB to Glacier—Multi-site—e.g., 10 gateways—1 PB+.
Example: Backup infra—backup-gateway (50 TB volumes), S3 sync, Glacier archive—scales to 100 TB across sites.
Use Cases and Scenarios
Basic: File sharing—e.g., SMB to S3. Backup: Volume snapshots—e.g., iSCSI to EBS—Tape—e.g., VTL to Glacier. DR: Multi-site—e.g., replicate to us-west-2. Hybrid: Cached—e.g., low-latency local access, S3 backend.
Edge Cases and Gotchas
Sync: Lag—e.g., slow uplink delays S3 writes—CacheDirty spikes—tune bandwidth. Cache: Full—e.g., 150 GiB limit blocks writes—expand or evict. Snapshots: Partial—e.g., interrupted sync—manual retry—EBS cost—e.g., 1 TB = $50/month. Tape: Retrieval—e.g., Glacier delays (3-5 hrs)—plan access—Barcode—e.g., duplicates fail. HA: Failover—e.g., IP conflicts—test failover—Gateway offline—e.g., no internet—local only.
Integration with Other Services
S3: Backend—e.g., s3://my-bucket. EBS: Snapshots—e.g., volume backups. Glacier: Archive—e.g., Tape Gateway. CloudWatch: Metrics—e.g., UploadBufferUsed—Events—e.g., cache refresh. IAM: Permissions—e.g., storagegateway:CreateSnapshot. VPC: Endpoints—e.g., private S3 access—EC2: VM hosting—e.g., gateway on t3.medium.
Overview
AWS DataSync, launched in 2018, is a managed data transfer service that automates and accelerates moving data between on-premises storage, AWS services, or other clouds—e.g., NFS to S3, EFS to EFS across regions. It’s built for speed (up to 10 Gbps per agent) and simplicity, handling backups, migrations, or data lake ingestion with encryption and scheduling. Picture a media firm syncing terabytes of video from on-prem NAS to S3 or a research team replicating datasets to EFS for ML—DataSync cuts transfer times from days to hours. From basics (one-time sync) to advanced (multi-site replication, bandwidth throttling), it scales to petabytes with minimal overhead.
Architecture and Core Components
DataSync is a regional service with an agent-based architecture connecting source and target locations via a secure, proprietary protocol. Key components:
- Agent: VM (VMware, Hyper-V, EC2)—e.g.,
datasync-agent-123—runs locally, transfers data. - Task: Job—e.g.,
aws datasync create-task—defines source, destination, schedule. - Location: Endpoint—e.g.,
s3://my-bucket,nfs://10.0.0.1/data—source or target storage. - Service: Control plane—e.g., AWS-managed—orchestrates transfers, tracks state.
- VPC Endpoint: Private link—e.g.,
vpce-123—keeps traffic off the public internet.
Flow: Agent reads source → Encrypts (TLS) → Streams to target—e.g., NFS → S3—state in DynamoDB, 99.9% SLA, 11 9’s durability on AWS side.
Features and Configuration
Basics: Agent—e.g., aws datasync create-agent --agent-name my-agent—Task—e.g., aws datasync create-task --source-location-arn arn:aws:datasync:us-east-1:123:location/loc-abc --destination-location-arn arn:aws:datasync:us-east-1:123:location/loc-xyz—Start—e.g., aws datasync start-task-execution. Intermediate: Schedule—e.g., daily at 2 AM—Filters—e.g., include *.csv—Verify—e.g., checksum post-transfer. Advanced: Bandwidth Limit—e.g., 10 Mbps cap—Multi-Agent—e.g., 10 Gbps aggregate—CloudWatch Metrics—e.g., BytesTransferred—Tags—e.g., aws datasync tag-resource. Config: IAM—e.g., datasync:CreateTask—Storage—e.g., S3, EFS, FSx—Network—e.g., Direct Connect. Limits: 100 tasks/agent, 50M files/task—soft limits.
Pricing
DataSync: $0.0125/GB transferred—e.g., 1 TB = $12.80. Storage: S3—e.g., $0.023/GB-month—EFS—e.g., $0.30/GB-month—FSx—e.g., $0.13/GB-month. Agent: Free—runs on your infra (e.g., EC2 t3.large, $0.0832/hr). Data Transfer: Out—e.g., $0.09/GB (non-AWS targets)—In—free. Free tier: None—$0 unless used. Example: Sync 1 TB NFS to S3 = $12.80 (transfer) + $23.55 (S3, 1 month) = $36.35 total.
Automation and Scaling
Scales to petabytes:
- Basic: Single agent—e.g., 1 TB to S3—
aws datasync start-task-execution—1 Gbps. - Intermediate: Scheduled—e.g., 10 TB nightly—Multi-task—e.g., 5 agents, 5 TB each—5 Gbps.
- Advanced: Multi-site—e.g., 10 agents, 100 TB—Throttling—e.g., 50 Mbps/site—Petabyte sync—e.g., 10 Gbps aggregate.
Example: Data lake—sync-task (50 TB from NAS to S3), scheduled, multi-agent—scales to 1 PB across regions.
Use Cases and Scenarios
Basic: Migration—e.g., NFS to S3. Backup: On-prem to EFS—e.g., daily sync. Analytics: NAS to S3—e.g., feed Redshift. DR: EFS cross-region—e.g., us-east-1 to us-west-2.
Edge Cases and Gotchas
Agent: Offline—e.g., no internet—task fails—deploy VPC endpoint—CPU—e.g., 100% peg halts sync—upsize VM. Transfer: Throttle—e.g., 1 Mbps starves bandwidth—adjust limit—Partial—e.g., network drop—restart task. Cost: Spike—e.g., 100 TB = $1,280—monitor usage—EFS—e.g., $300/TB-month—use S3 where possible. Verify: Mismatch—e.g., corrupted file—re-run with checksum—Scale—e.g., 50M+ files—split tasks.
Integration with Other Services
S3: Target—e.g., s3://my-bucket. EFS: Source/Target—e.g., efs://fs-123. FSx: Windows shares—e.g., fsx://fs-456. CloudWatch: Metrics—e.g., TaskExecutionStatus—Events—e.g., task complete. IAM: Permissions—e.g., datasync:StartTaskExecution. VPC: Endpoints—e.g., private sync—EC2: Agent host—e.g., t3.large.